Facial recognition triggering automation
-
I have optimized my facial recognition scheme and discovered a few things:
My wifi doorbell, the RCA HSDB2, was overloaded by having to provide too many concurrent rtsp streams which was causing the streams themselves to be unreliable:
Cloud stream
stream to QNAP NVR
stream to home assistant (regular)
stream to home assistant facial recognition.I decided to use the proxy function of the QNAP NVR to now only pull 2 streams from the doorbell and have the NVR be the source for home assistant. This stabilized the system quite a bit.
The second optimization was to find out that by default home assistant processes images every 10s. It made me think that the processing was slow but it turns out that it was just not being triggered frequently enough. I turned it up to 2s and now I have a working automation to trigger an openLuup scene, triggering opening a doorlock with conditionals on house mode and geofence. Now I am looking to offload this processing from the cpu to an intel NCS2 stick so I might test some other components than Dlib to make things run even faster.
-
This is what I am looking at implementing at the moment:
It is an API which could potentially work with an openLuup plugin.
-
Well after much consideration, I decided to add an nVidia GPU to my NAS which is already hosting all my automation VMs to support this instead of getting a dedicated SBC with a coprocessor. It seems to be the simplest and most cost effective way while probably offering the best performance and extendibility for future AI.
-
Your hardware will never cease to amaze me! I bet one of your tesla cards costs more than my entire setup which is already not what one would call puny... COVID19 seems to have jacked up all the prices and made availability of hardware quite limited. I am seeing the GPUs I was shopping all going out of stock or raising prices within a couple of days...
Back on the topic, my wife was pretty happy with the door unlocking within 3s of us showing up in front of the doorbell. I can sense a delay for the integration to pickup the video stream, resolve it and run the facial recognition which is why I am looking at testing it with a GPU which may open the door to do other things like recognizing when a package was delivered and eventually filter out camera motion signals to only show when there is an actual person. I am even thinking about detecting deers in the yard to start my sprinkler to scare them away when they come to eat my flowers...
-
So I have not yet received my GPU but discovered that most of the reliability issues I am having is around getting a snapshot from my doorbell with ffmpeg. It seems to fail to get a picture to process between 15 and 30% of the time and I can't figure out why as I see no error from the proxy streamer. It does take ~2-10s for a full process using a single thread from my CPU at the moment and the CPU does not even appear to be overloaded during processing, hitting 12% load. hope the GPU will fix this.
-
Further info on this. Because my doorbell cam stream resolution is pretty high (1536x2048), and I am running all the automation within virtual machines, the iGPU of the CPU is not getting passed through so there is no hardware acceleration for the video stream decoding. This is why I am having dropped frames. I got the thing to work very reliably now, it is just a bit too slow to my taste (2-10s). I really need a GPU to passthrough to the VM for this and have it accelerate the video decoding and the deep learning facial recognition. Decided to cancel my unshipped 1650 super and got myself a 2060 super instead which has neural processors... It also mean that I will have to wait even longer...

-
Further info on this. Because my doorbell cam stream resolution is pretty high (1536x2048), and I am running all the automation within virtual machines, the iGPU of the CPU is not getting passed through so there is no hardware acceleration for the video stream decoding. This is why I am having dropped frames. I got the thing to work very reliably now, it is just a bit too slow to my taste (2-10s). I really need a GPU to passthrough to the VM for this and have it accelerate the video decoding and the deep learning facial recognition. Decided to cancel my unshipped 1650 super and got myself a 2060 super instead which has neural processors... It also mean that I will have to wait even longer...
-
Been coding some python to modify Home Assistant components to use the GPU both for video stream decoding and the API calls for recognition inferences. Speed is much improved and CPU/RAM load massively reduced. Pretty amazing how much memory one inference uses. My GPU has 8GB and uses 3GB to process one video stream with dlib... The inference time has gone from 2s down to near instant now. Most of the lag if any is to capture the screenshot to process.
-
A quick writeup on what I did on my VM:
- Powered off my NAS and inserted in the GPU. Power on the NAS and setup the GPU to passthrough into the VM from the VM supervisor (In my case QNAP Virtual Station)
- Install the Geforce driver. https://www.nvidia.com/Download/index.aspx?lang=en-us
- Install Cuda Toolkit https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
- Install cuDNN (downloading the library requires registering for a dev account with nVidia)
- Compile ffmpeg to support GPU and install it: https://developer.nvidia.com/ffmpeg
- Compile dlib to support CUDA: https://stackoverflow.com/questions/49731346/compile-dlib-with-cuda and install it
 GitHub - davisking/dlib: A toolkit for making real world machine learning and data analysis applications in C++
GitHub - davisking/dlib: A toolkit for making real world machine learning and data analysis applications in C++
A toolkit for making real world machine learning and data analysis applications in C++ - davisking/dlib
- Changed my home assistant camera ffmpeg command to add the nvidia header as documented by the ffmpeg documentation above.
- Modified Home Assistant's dlib component to activate cnn model. This is the one file I changed: https://github.com/rafale77/home-assistant/blob/dev/homeassistant/components/dlib_face_identify/image_processing.py
Not going to detail the home assistant configuration changes here since they are very installation dependent. Also I did this on linux but it is very platform agnostic...
9. Create an openLuup virtual device (can be a motion or door sensor, in my case I used a virtual switch)
10. Bind the Home Assistant entity to that created device using home assistant automation and an API calls updating switch status and another variable capturing the name of the person recognized.
11. Created a scene with the code below to resolve what face was recognized and unlock the door if house mode just changed to home and nobody has yet entered the house, a condition I isolate using a global variable in openLuup (greet):local Fid = **virtual switch id** local lockid = **id of the lock** local SS_SID = "urn:micasaverde-com:serviceId:SecuritySensor1" local VS_SID = "urn:upnp-org:serviceId:VSwitch1" local face = luup.variable_get(VS_SID,"Text2",Fid) local last = luup.variable_get(SS_SID, "LastTrip",Fid) if string.find(face, "hubby") ~= nil then face = string.format("Hubby @ %s", os.date()) luup.variable_set(SS_SID, "LastFace", face,Fid) if greet == 1 then luup.variable_set(SS_SID, "LastTrip", os.time(),Fid) luup.call_action("urn:micasaverde-com:serviceId:DoorLock1","SetTarget",{newTargetValue = 0}, lockid) sendnotifcam("doorbell") end elseif string.find(face, "wify") ~= nil then face = string.format("wify @ %s", os.date()) luup.variable_set(SS_SID, "LastFace", face,Fid) if greet == 1 then luup.variable_set(SS_SID, "LastTrip", os.time(),Fid) luup.call_action("urn:micasaverde-com:serviceId:DoorLock1","SetTarget",{newTargetValue = 0}, lockid) sendnotifcam("doorbell2") end else return false endNote that I also have a global function to send a push notification with snapshots in my startup lua. (sendnotifcam)
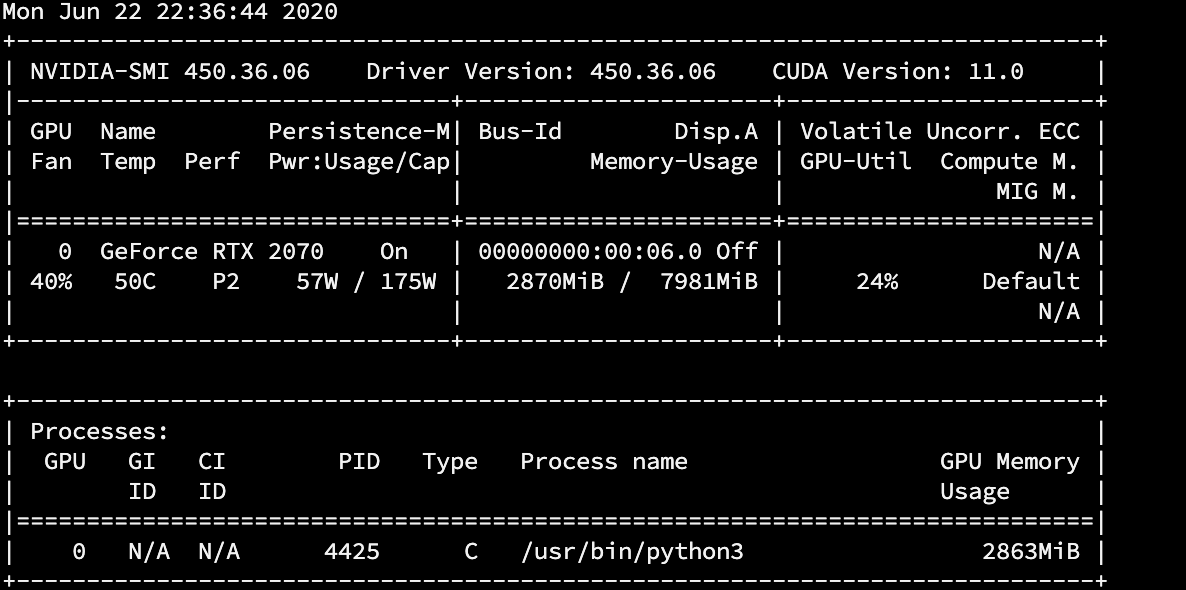
This is the peak load when the GPU is resolving the face from my doorbell, which I set to once per second:
-
because of my choice of driver/cuda and cudnn version... I am on the bleeding edge and am having to compile everything from source... opencv is a bit of a nightmare with me having to change some of the source code but some other libraries are also missing. I am currently doing caffe/pytorch... after completing ffmpeg and dlib... All good fun and learning a lot about deep learning but it is pretty time consuming.
-
Alright!!! I got one thing fixed on home assistant's camera components:
So the issue is that all these image processing component work by grabbing a snapshot from a camera component.
The issue with all these camera components is that they actually don't stream in the background in home assistant and therefore every time one needs to get a snapshot, a new connection needs to be negotiated and established. This process, uses ffmpeg and the time it takes to establish this connection varies a lot even for one same camera. It can also fail for various reasons.
Now this has cause my facial recognition to have latency varying by a lot from instant to near 10s in my extensive testing. Grabbing the snapshot itself only takes 0.03s and processing it now with my GPU also only takes 0.1s... I have been chasing this latency problem and have even gone as far as learning enough Python coding to try rewrite the ffmpeg camera component using threading. Then I discovered this wrapper: https://github.com/statueofmike/rtspAnd have now integrated it into the ffmpeg component. Boom! Home assistant now constantly stream from the camera (technically a proxy which is already on the same machine) and never has any lag. I also took advantage of this to fix a few bugs in the amcrest camera component... which I will be posting on my fork of home assistant.
One more problem resolved!
Now opencv, tensorflow and pytorch are not supporting the latest nvidia cuda and cudnn versions yet so I will sit back on these and use dlib which I also modified to make use of the GPU.
My mods for reference:
Next step: Object detection! let's try people and packages... this would eliminate false motion alarms from cameras when we get a windstorm here.
-
I have not been posting in this thread for some time but it is an area I have been spending my spare time on... learning about this area of active research....
From the previous component I rewrote, I have now evolved my face recognition component with different models. Here a summary table bellow:

With some interesting reads:
-
I have not been posting in this thread for some time but it is an area I have been spending my spare time on... learning about this area of active research....
From the previous component I rewrote, I have now evolved my face recognition component with different models. Here a summary table bellow:
With some interesting reads:
I have taken another look at this and have now drastically modified my fork of homeassistant and deviated from the main branch:
- I added a state variable to the image processing component so as to turn on and off the processing from openLuup. (and giving the ability to turn on only upon camera movement detection.)
- Massively optimized the video frame handling so that it doesn't get converted into a variety of formats. It's still not perfect since it still goes from the GPU decoder to the CPU, runs some processing (resizing mostly) and gets sent back to the GPU for model inference but I will get there eventually.
- Huge improvement in the face detection model where I refactored the model to take out some constants, preventing them from getting recalculated for every frame and more than doubled the inference speed.
- Updated my object detection model to this improved version of Yolo which is more accurate and only cost a tiny bit more:
GitHub - WongKinYiu/ScaledYOLOv4: Scaled-YOLOv4: Scaling Cross Stage Partial Network
Scaled-YOLOv4: Scaling Cross Stage Partial Network - WongKinYiu/ScaledYOLOv4
Note: I am heavily relying on pytorch as my neural network framework (supported by facebook but initiated as a lua project before it moved to python) and opencv for video and image processing (supported by intel).
")