Facial recognition explained and Customized Home-Assistant components
-
Sharing what I have learned and some modifications to components with their benefits.
On home assistant/python3, facial recognition involves the following steps:- Establishing and maintaining a camera stream (over rtsp or http protocol)
- Have the ability to extract a single frame from the open stream in order to process it
- Pre process using the same steps as a video frame and store in memory a predetermined number of pictures as the known people to later compare with. In reality what is being compared are arrays of numbers generated by a model.
- Run a face detection and localization on the frame using one model
- Using the resulting location of 4., Extract from the picture, the face and encode it into a array of number
- Run a classification or comparison between the pre-set faces and the face on the video and spit out the "inference" or "prediction" to determine if they are close enough to be the same person.
Even though a few components have been created on home-assistant for many years to do this, I ran into challenges which forced me to improve/optimize the process.
- Home Assistant's camera does not establish and keep open a stream in the background. It can open one on demand through its UI but doesn't keep it open. This forces the facial camera component to have to re-establish a new stream to get a single frame every time it needs to process an image causing up to 2s of delays, unacceptable for my application. I therefore rewrote the ffmpeg camera component to use opencv and maintain a stream within a python thread and since I have a GPU, I decided to decode the video using my GPU to relieve the CPU. This also required playing with some subtleties to avoid uselessly decoding frames we won't process while still needing to remove them from the thread buffer.
- The frame extraction was pretty challenging using ffmpeg which is why I opted to use opencv instead, as it executes the frame synchonization and alignment from the byte stream for us.
- The pre-set pictures was not a problem and a part of every face component.
- I started with the dlib component which had two models for ease of use. It makes use of the dlib library and the "facial_recognition" wrapper which has a python3 API but the CNN model requires a GPU and while it works well for me, turned out not to be the best as explained in this article and also quite resource intensive:https://www.learnopencv.com/face-detection-opencv-dlib-and-deep-learning-c-python/
So I opted to move to the opencv DNN algorithm instead. Home Assistant has an openCV component but it is a bit generic and I couldn't figure out how to make it work. In any case, it did not have the steps 5 and 6 I wanted. - For the face encoding step, I struggled quite a bit as it is quite directly connected to what option I would chose for step 6. From my investigation, I came to this: https://www.pyimagesearch.com/2018/09/24/opencv-face-recognition/
"*Use dlib’s embedding model (but not it’s k-NN for face recognition)
In my experience using both OpenCV’s face recognition model along with dlib’s face recognition model, I’ve found that dlib’s face embeddings are more discriminative, especially for smaller datasets.
Furthermore, I’ve found that dlib’s model is less dependent on:
Preprocessing such as face alignment
Using a more powerful machine learning model on top of extracted face embeddings
If you take a look at my original face recognition tutorial, you’ll notice that we utilized a simple k-NN algorithm for face recognition (with a small modification to throw out nearest neighbor votes whose distance was above a threshold).The k-NN model worked extremely well, but as we know, more powerful machine learning models exist.
To improve accuracy further, you may want to use dlib’s embedding model, and then instead of applying k-NN, follow Step #2 from today’s post and train a more powerful classifier on the face embeddings.*"
The trouble from my research is that I can see some people have tried but I have not seen posted anywhere a solution to translating the location array output from the opencv dnn model into a dlib rect object format for dlib to encode. Well, I did just that...
- For now I am sticking with the simple euclidian distance calculation and a distance threshold to determine the face match as it has been quite accurate for me but the option of going for a much more complex classification algorithm is open... when I get to it.
So in summary, the outcome is modifications to:
A. the ffmpeg camera component to switch to opencv and enable background maintenance of a stream with one rewritten file:
https://github.com/rafale77/home-assistant/blob/dev/homeassistant/components/ffmpeg/camera.py
B. Changes to the dlib face recognition component to support the opencv face detection model:
https://github.com/rafale77/home-assistant/blob/dev/homeassistant/components/dlib_face_identify/image_processing.py
C. Modified face_recognition wrapper to do the same, enabling conversion between dlib and opencv
D. And additions of the new model to the face_recognition library involving adding a couple of files: face_recognition/face_recognition/api.py at master · rafale77/face_recognition
face_recognition/face_recognition/api.py at master · rafale77/face_recognition
The world's simplest facial recognition api for Python and the command line - rafale77/face_recognition
face_recognition_models/face_recognition_models/__init__.py at master · rafale77/face_recognition_models
Trained models for the face_recognition python library - rafale77/face_recognition_models
face_recognition_models/face_recognition_models/models at master · rafale77/face_recognition_models
Trained models for the face_recognition python library - rafale77/face_recognition_models
Overall these changes significantly improved speed and decreased cpu and gpu utilization rate over any of the original dlib components.
At the moment the CUDA use for this inference is broken on openCV using the latest CUDA so I have not even switched on the GPU for facial detection yet (it worked fine using the dlib cnn model) but a fix may already have been posted so I will recompile openCV shortly...Edit: Sure enough openCV is fixed. I am running the face detection on the GPU now.
-
Maybe this could help:
The four computational steps:
The model training (the bases to compare to) must be done before hand.
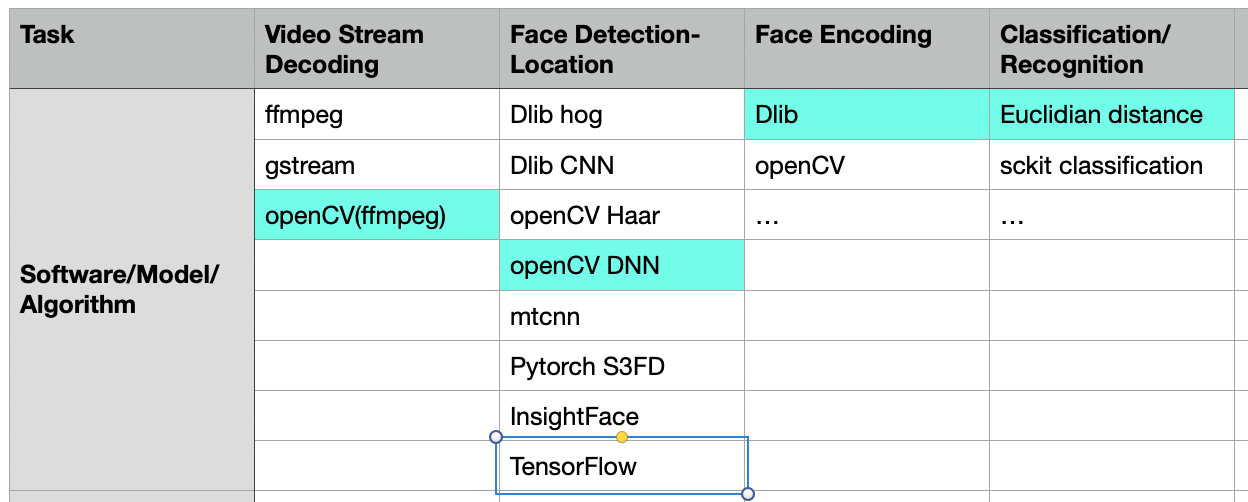
Each step can be either done by the CPU or the GPU. I highlighted in teal my current selection for which I shared the code.
")
For the last column... I am just getting started...
https://machinelearningmastery.com/hyperparameters-for-classification-machine-learning-algorithms/ -
Well now I can confirm, It is drastically more accurate if trained with a large enough dataset. I loaded 30 random face pictures, 30 of my own and 30 of the wife and the thing is a little more accurate than the previous approach. Pretty happy with the outcome.
So the recognition (encoding and classification) uses machine learning which is easy enough to run on the CPU, the face detection is more complex and relies on deep learning. I have basically resolved to assemble my own system composing from various model sources. Pretty satisfactory outcome.
When I'll have more time, I will investigate some newer award winning ones like insightface, deepstack... -
I have been optimizing the code further to have less dependencies (relying directly on the dlib library instead of a wrapper for it) and learned some more about convoluted neural network inferences... fascinating field. I also changed the jitter parameter from 1 to 10 which should help the accuracy.
core/homeassistant/components/dlib_face_identify/image_processing.py at live · rafale77/core
:house_with_garden: Open source home automation that puts local control and privacy first - rafale77/core
The original dlib model has scored 99.17% at the LFW benchmark and my mods sped up the face detection and probably improved accuracy by using a classifier rather than just an Euclidean distance, enlarging the face detection and training set, and the increase of the jitter parameter. Looking around for what is available, the only thing that is potentially better is the retinaface detection + arcface encoding which potentially could improve the angled recognition. I am almost done implementing it for testing but it probably is overkill for my doorbell...
")
