



Quality of Life Request: Update Button
-
@Cadwizzard said:
Just like back in the old Vera days
How soon we forget the tales of bricked Veras. Who among us didn't have a little sense that they were playing Russian roulette every time we hit that button?
Unsure how easy update would be with the various ways of implementing MSR inside/outside docker etc
OK. He hits it on the head here. Let me explain some of the complications and my reservations around this.
The biggest pitfall is for docker users, IMO; that's the majority of you. The first thing you need to understand about docker is that the image and the container are separate objects in the system. The container is created from the image, but it's basically a copy, not linked in any meaningful way. The container can change, so that's good — I can download a release package and apply it to the container, restart, and the container will now be running the new release files. Unfortunately, that has no bearing on what happens to the image. Changing files in the container does nothing to the image. So let's take a scenario... @tunnus (Docker, Synology) downloads the image for Reactor 22274 and creates a container for it, so he's now running 22274. A little later, 22291 is released, so he hits the handy, flashy new "Upgrade" button and the container is upgraded in place. Perfect. Except, not... his image is still 22274. Stay with me now... In all likelihood, because of the "ease" of the automated upgrade, tunnus never needs to download a new image again (so he thinks), so he never bothers (it's a pain anyway on Synology, I'll agree). So build 22293 comes along, and then 22302, and then 22305, and then 22308, and he upgrades to all of them using the automated process, but the image is still sitting there on his NAS at 22274. The problem strikes if, for any reason (DSM major upgrade?), he decides to reset and rebuild the container, or delete it. He will get.... 22274. Because that's the image he has.
Can I make docker download the newer image as part of the upgrade process? No. Reactor is running inside the container, and the container, by definition, contains Reactor and keeps it from doing anything external to the container (except the limited data volume that's specifically created for the single purpose). So the running Reactor instance has no ability whatsoever to cause docker/DSM to pull later images. Pulling a new image and rebuilding the container is the real "right" way to upgrade, but it's not possible to automate it from within the container itself (and it's darned clunky in Synology's UI, unfortunately).
It's not hard to imagine that this problem would not bite him for months or years. But when it bites, it has the potential to bite hard. Imagine along Reactor's evolutionary path from 22274 to a future 24107 (released in 2024, all automated updates between, no image refreshes), there are changes that needed to be made to the data structures of rules, reactions, stored states, etc. (not at all hard to imagine, it actually happens all the time). It is easy, although sometimes a bit cumbersome, for me to provide forward compatibility: to make sure that newer versions of code read the old data and upgrade the structures, and the mechanisms for those upgrades remain in the code for some time. But there is no way under the sun for 22274, now running once again unexpectedly, to know what to do with data from the future 24107 build, and there's a chance it could do something really bad to it. Now tunnus has an old version running in his container with corrupt data. I hope he has a backup.
I'll take the opportunity to say that this is a cautionary tale for all of you who stay on older builds. I keep the code that reads and upgrades the data, when needed, for a while, so that people who skip a few upgrades can safely do so and "jump in time" when they are ready to apply a new build, but I don't and won't keep that code forever; it becomes a maintenance nightmare and it's beyond my available time and sensibilities to test every possible combination of upgrades between versions. If you're running on a Reactor that's more than a year out (21307 or earlier), you're playing with fire as far as I'm concerned, and you should not expect a smooth upgrade when you get around to it. You may need to upgrade to an interim build still available, which works for bare-metal, but isn't an option for docker users. And before the "I can't have something like that in my home" people start in here, please know that I'm sorry that the free software I offer you and for which I provide ready, quick, and free ongoing support (and upgrades) isn't perfectly to your liking. If you don't like the way it works, you have alternatives, and I fully support your freedom to choose them.
To continue with @Cadwizzard's point: this is equally or more egregious, unfortunately, for docker-compose users, because up to this point, the recommended way for stopping Reactor when using docker-compose is to run
docker-compose down. This causes Reactor to stop, but also deletes the container. Any upgrades applied to the container are lost in that instant, because the container is discarded. When you later rundocker-compose up -d, the container is re-created from the (old) image, and will be whatever version that image is. Maybe not a disaster, maybe it is. This could be addressed by retraining docker-compose users to usedocker-compose stoprather thandocker-compose down, but the distinction would need to be taught (and learned) as both are useful, and the infrequency of use of these commands would likely suffer from brain-drain over time (i.e. when to use which and what their side effects could be/will be lost on the user a few months from now). But it's such a subtle distinction that people will shoot themselves in the foot easily and regularly, I fear.Bare-metal is somewhat easier, because at least the process can be assured it's writing on the one and only (relevant) image, in the install directory, so that's a bit of relief. Unfortunately, a lot of people really don't understand Linux file permissions, their relations to users and groups, etc., and routinely goof up the permissions of files all over their system, including in the Reactor install directory. This isn't a problem for them after the first "fix," because thereafter they do the manual upgrades the same way, logged in as the same user (in some cases, even as root, which is a serious no-no), and so it works for them as that user in that case, good enough. But for an automated process running in an unprivileged environment, it can mean that some files aren't writable, and the upgrade only half-happens... the upgrade process crashes, some files are new and some are old, and the Reactor install is basically dead and broken. I can't fix the permissions from the running instance, because it's running as an unprivileged user (well, hopefully; woe unto those who run anything as root). The user then manually applies the upgrade to recover the system, which goes fine because of course he's running the privileged user with the right permissions. A bug/post for the upgrade process then gets reported, and I then spend hours or days going back and forth, digging through the user's 3,000+ files in a typical Reactor install, looking for the broken ones and teaching the user how to fix them. (Permissions and their potential brokenness is also an issue for doing automated backups/restores, since that was mentioned as well.)
Oh, and then there's Windows. I won't even start. I've already written a book (again).
With regard to the suggestion of a standard install method: (a) there is no "one size fits all" — what works for Ubuntu doesn't work for Synology DSM or QNAP, and certainly not for Windows; and (b) the install methods that are recommended are all carefully documented; experience shows that I can write out every detail I can think of, and what actually happens on the user's system is 100% of that or some amount less, or the user has some condition in their system/environment that I could not/did not anticipate that causes problems. My preferred method for most users is docker (and specifically, with docker-compose), because the container strategy removes some of these risks, but that's not always the easiest for their environment (e.g. Synology has docker but no -compose), and the accepted mechanisms for upgrading containers in the docker world in general are ironically exactly the subject of complaints by OP and others here, despite the relative ubiquity and ease of these mechanisms.
The point is, there is no panacaea here. You run these systems, not me. You do things I have no knowledge of, and sometimes those things bite back. The majority of my time supporting this product is troubleshooting your environments, not my code (I'm not saying I'm perfect — I make mistakes and bugs are a reality, but they're not the majority of support issues here in terms of time spent). Anything and everything I do in the system is looked at not just through the lens of whether it's convenient for the user, but very much through the lens of supportability. There are lots of features I get asked to do, and as you've seen (even recently), there are some that I refuse to consider simply because it would make the system less supportable, in my view. As features get added, not only is the usability of the system required to improve, but its quality is expected to improve as well (fewer bugs, better support, etc.) — those are my expectations, which I'm sure you share. If one doesn't consider supportability (and that means both in user support and code maintenance/reliability/scalability), one ends up with a lot of features that nobody asked for, don't work, and aren't usable (I can point you in the direction of such a product as an alternative if you're really interested in that).
There is a running, hidden upgrade process in the current build. I've been experimenting with this for a bit, getting to learn it, and discovering these issues. It's not that I won't consider making it available; I'm still studying it, and pondering the wisdom of it. Maybe sometimes I worry too much about things like this, I don't know. But when it goes wrong, there's nobody but you and me to fix it, and there's a lot of you and only one of me, so as I said in another recent conversation, handing out something that feels like a grenade with no pin sometimes doesn't seem like the best idea to me, and there are probably other things this system needs to do that I can better spend my time on. Maybe this is one of those things.
I'll leave this one up to you guys. If you can tolerate these side effects, I'll release the feature. But know that if you break your install because (docker) you somehow delete the container and recreate it from an old image, or (bare-metal) your install has broken permissions or other issues that the upgrade process can't work through, my answer will be short: that's a risk you accepted, do a clean reinstall from a current image, restore your config/state backup, and start over.
Author of Multi-system Reactor and Reactor, DelayLight, Switchboard, and about a dozen other plugins that run on Vera and openLuup.
-
@Cadwizzard said:
Just like back in the old Vera days
How soon we forget the tales of bricked Veras. Who among us didn't have a little sense that they were playing Russian roulette every time we hit that button?
Unsure how easy update would be with the various ways of implementing MSR inside/outside docker etc
OK. He hits it on the head here. Let me explain some of the complications and my reservations around this.
The biggest pitfall is for docker users, IMO; that's the majority of you. The first thing you need to understand about docker is that the image and the container are separate objects in the system. The container is created from the image, but it's basically a copy, not linked in any meaningful way. The container can change, so that's good — I can download a release package and apply it to the container, restart, and the container will now be running the new release files. Unfortunately, that has no bearing on what happens to the image. Changing files in the container does nothing to the image. So let's take a scenario... @tunnus (Docker, Synology) downloads the image for Reactor 22274 and creates a container for it, so he's now running 22274. A little later, 22291 is released, so he hits the handy, flashy new "Upgrade" button and the container is upgraded in place. Perfect. Except, not... his image is still 22274. Stay with me now... In all likelihood, because of the "ease" of the automated upgrade, tunnus never needs to download a new image again (so he thinks), so he never bothers (it's a pain anyway on Synology, I'll agree). So build 22293 comes along, and then 22302, and then 22305, and then 22308, and he upgrades to all of them using the automated process, but the image is still sitting there on his NAS at 22274. The problem strikes if, for any reason (DSM major upgrade?), he decides to reset and rebuild the container, or delete it. He will get.... 22274. Because that's the image he has.
Can I make docker download the newer image as part of the upgrade process? No. Reactor is running inside the container, and the container, by definition, contains Reactor and keeps it from doing anything external to the container (except the limited data volume that's specifically created for the single purpose). So the running Reactor instance has no ability whatsoever to cause docker/DSM to pull later images. Pulling a new image and rebuilding the container is the real "right" way to upgrade, but it's not possible to automate it from within the container itself (and it's darned clunky in Synology's UI, unfortunately).
It's not hard to imagine that this problem would not bite him for months or years. But when it bites, it has the potential to bite hard. Imagine along Reactor's evolutionary path from 22274 to a future 24107 (released in 2024, all automated updates between, no image refreshes), there are changes that needed to be made to the data structures of rules, reactions, stored states, etc. (not at all hard to imagine, it actually happens all the time). It is easy, although sometimes a bit cumbersome, for me to provide forward compatibility: to make sure that newer versions of code read the old data and upgrade the structures, and the mechanisms for those upgrades remain in the code for some time. But there is no way under the sun for 22274, now running once again unexpectedly, to know what to do with data from the future 24107 build, and there's a chance it could do something really bad to it. Now tunnus has an old version running in his container with corrupt data. I hope he has a backup.
I'll take the opportunity to say that this is a cautionary tale for all of you who stay on older builds. I keep the code that reads and upgrades the data, when needed, for a while, so that people who skip a few upgrades can safely do so and "jump in time" when they are ready to apply a new build, but I don't and won't keep that code forever; it becomes a maintenance nightmare and it's beyond my available time and sensibilities to test every possible combination of upgrades between versions. If you're running on a Reactor that's more than a year out (21307 or earlier), you're playing with fire as far as I'm concerned, and you should not expect a smooth upgrade when you get around to it. You may need to upgrade to an interim build still available, which works for bare-metal, but isn't an option for docker users. And before the "I can't have something like that in my home" people start in here, please know that I'm sorry that the free software I offer you and for which I provide ready, quick, and free ongoing support (and upgrades) isn't perfectly to your liking. If you don't like the way it works, you have alternatives, and I fully support your freedom to choose them.
To continue with @Cadwizzard's point: this is equally or more egregious, unfortunately, for docker-compose users, because up to this point, the recommended way for stopping Reactor when using docker-compose is to run
docker-compose down. This causes Reactor to stop, but also deletes the container. Any upgrades applied to the container are lost in that instant, because the container is discarded. When you later rundocker-compose up -d, the container is re-created from the (old) image, and will be whatever version that image is. Maybe not a disaster, maybe it is. This could be addressed by retraining docker-compose users to usedocker-compose stoprather thandocker-compose down, but the distinction would need to be taught (and learned) as both are useful, and the infrequency of use of these commands would likely suffer from brain-drain over time (i.e. when to use which and what their side effects could be/will be lost on the user a few months from now). But it's such a subtle distinction that people will shoot themselves in the foot easily and regularly, I fear.Bare-metal is somewhat easier, because at least the process can be assured it's writing on the one and only (relevant) image, in the install directory, so that's a bit of relief. Unfortunately, a lot of people really don't understand Linux file permissions, their relations to users and groups, etc., and routinely goof up the permissions of files all over their system, including in the Reactor install directory. This isn't a problem for them after the first "fix," because thereafter they do the manual upgrades the same way, logged in as the same user (in some cases, even as root, which is a serious no-no), and so it works for them as that user in that case, good enough. But for an automated process running in an unprivileged environment, it can mean that some files aren't writable, and the upgrade only half-happens... the upgrade process crashes, some files are new and some are old, and the Reactor install is basically dead and broken. I can't fix the permissions from the running instance, because it's running as an unprivileged user (well, hopefully; woe unto those who run anything as root). The user then manually applies the upgrade to recover the system, which goes fine because of course he's running the privileged user with the right permissions. A bug/post for the upgrade process then gets reported, and I then spend hours or days going back and forth, digging through the user's 3,000+ files in a typical Reactor install, looking for the broken ones and teaching the user how to fix them. (Permissions and their potential brokenness is also an issue for doing automated backups/restores, since that was mentioned as well.)
Oh, and then there's Windows. I won't even start. I've already written a book (again).
With regard to the suggestion of a standard install method: (a) there is no "one size fits all" — what works for Ubuntu doesn't work for Synology DSM or QNAP, and certainly not for Windows; and (b) the install methods that are recommended are all carefully documented; experience shows that I can write out every detail I can think of, and what actually happens on the user's system is 100% of that or some amount less, or the user has some condition in their system/environment that I could not/did not anticipate that causes problems. My preferred method for most users is docker (and specifically, with docker-compose), because the container strategy removes some of these risks, but that's not always the easiest for their environment (e.g. Synology has docker but no -compose), and the accepted mechanisms for upgrading containers in the docker world in general are ironically exactly the subject of complaints by OP and others here, despite the relative ubiquity and ease of these mechanisms.
The point is, there is no panacaea here. You run these systems, not me. You do things I have no knowledge of, and sometimes those things bite back. The majority of my time supporting this product is troubleshooting your environments, not my code (I'm not saying I'm perfect — I make mistakes and bugs are a reality, but they're not the majority of support issues here in terms of time spent). Anything and everything I do in the system is looked at not just through the lens of whether it's convenient for the user, but very much through the lens of supportability. There are lots of features I get asked to do, and as you've seen (even recently), there are some that I refuse to consider simply because it would make the system less supportable, in my view. As features get added, not only is the usability of the system required to improve, but its quality is expected to improve as well (fewer bugs, better support, etc.) — those are my expectations, which I'm sure you share. If one doesn't consider supportability (and that means both in user support and code maintenance/reliability/scalability), one ends up with a lot of features that nobody asked for, don't work, and aren't usable (I can point you in the direction of such a product as an alternative if you're really interested in that).
There is a running, hidden upgrade process in the current build. I've been experimenting with this for a bit, getting to learn it, and discovering these issues. It's not that I won't consider making it available; I'm still studying it, and pondering the wisdom of it. Maybe sometimes I worry too much about things like this, I don't know. But when it goes wrong, there's nobody but you and me to fix it, and there's a lot of you and only one of me, so as I said in another recent conversation, handing out something that feels like a grenade with no pin sometimes doesn't seem like the best idea to me, and there are probably other things this system needs to do that I can better spend my time on. Maybe this is one of those things.
I'll leave this one up to you guys. If you can tolerate these side effects, I'll release the feature. But know that if you break your install because (docker) you somehow delete the container and recreate it from an old image, or (bare-metal) your install has broken permissions or other issues that the upgrade process can't work through, my answer will be short: that's a risk you accepted, do a clean reinstall from a current image, restore your config/state backup, and start over.
One more class of knowledge! Really the desire to have an automatic process would be very good, but your explanation makes clear the difficulty and risks, and I do not want to have it. As you said, the errors we generate are enough, I don't want to implement more risks. I think almost everyone here has a wife, so better to stay in the safety of the system working.
Well let's remove this from wishlist request, and could you share this list so we know everything that's coming in the future? Also put an item, display the status widget, in a window/iframe inside the HE dashboard
")
-
@Cadwizzard said:
Just like back in the old Vera days
How soon we forget the tales of bricked Veras. Who among us didn't have a little sense that they were playing Russian roulette every time we hit that button?
Unsure how easy update would be with the various ways of implementing MSR inside/outside docker etc
OK. He hits it on the head here. Let me explain some of the complications and my reservations around this.
The biggest pitfall is for docker users, IMO; that's the majority of you. The first thing you need to understand about docker is that the image and the container are separate objects in the system. The container is created from the image, but it's basically a copy, not linked in any meaningful way. The container can change, so that's good — I can download a release package and apply it to the container, restart, and the container will now be running the new release files. Unfortunately, that has no bearing on what happens to the image. Changing files in the container does nothing to the image. So let's take a scenario... @tunnus (Docker, Synology) downloads the image for Reactor 22274 and creates a container for it, so he's now running 22274. A little later, 22291 is released, so he hits the handy, flashy new "Upgrade" button and the container is upgraded in place. Perfect. Except, not... his image is still 22274. Stay with me now... In all likelihood, because of the "ease" of the automated upgrade, tunnus never needs to download a new image again (so he thinks), so he never bothers (it's a pain anyway on Synology, I'll agree). So build 22293 comes along, and then 22302, and then 22305, and then 22308, and he upgrades to all of them using the automated process, but the image is still sitting there on his NAS at 22274. The problem strikes if, for any reason (DSM major upgrade?), he decides to reset and rebuild the container, or delete it. He will get.... 22274. Because that's the image he has.
Can I make docker download the newer image as part of the upgrade process? No. Reactor is running inside the container, and the container, by definition, contains Reactor and keeps it from doing anything external to the container (except the limited data volume that's specifically created for the single purpose). So the running Reactor instance has no ability whatsoever to cause docker/DSM to pull later images. Pulling a new image and rebuilding the container is the real "right" way to upgrade, but it's not possible to automate it from within the container itself (and it's darned clunky in Synology's UI, unfortunately).
It's not hard to imagine that this problem would not bite him for months or years. But when it bites, it has the potential to bite hard. Imagine along Reactor's evolutionary path from 22274 to a future 24107 (released in 2024, all automated updates between, no image refreshes), there are changes that needed to be made to the data structures of rules, reactions, stored states, etc. (not at all hard to imagine, it actually happens all the time). It is easy, although sometimes a bit cumbersome, for me to provide forward compatibility: to make sure that newer versions of code read the old data and upgrade the structures, and the mechanisms for those upgrades remain in the code for some time. But there is no way under the sun for 22274, now running once again unexpectedly, to know what to do with data from the future 24107 build, and there's a chance it could do something really bad to it. Now tunnus has an old version running in his container with corrupt data. I hope he has a backup.
I'll take the opportunity to say that this is a cautionary tale for all of you who stay on older builds. I keep the code that reads and upgrades the data, when needed, for a while, so that people who skip a few upgrades can safely do so and "jump in time" when they are ready to apply a new build, but I don't and won't keep that code forever; it becomes a maintenance nightmare and it's beyond my available time and sensibilities to test every possible combination of upgrades between versions. If you're running on a Reactor that's more than a year out (21307 or earlier), you're playing with fire as far as I'm concerned, and you should not expect a smooth upgrade when you get around to it. You may need to upgrade to an interim build still available, which works for bare-metal, but isn't an option for docker users. And before the "I can't have something like that in my home" people start in here, please know that I'm sorry that the free software I offer you and for which I provide ready, quick, and free ongoing support (and upgrades) isn't perfectly to your liking. If you don't like the way it works, you have alternatives, and I fully support your freedom to choose them.
To continue with @Cadwizzard's point: this is equally or more egregious, unfortunately, for docker-compose users, because up to this point, the recommended way for stopping Reactor when using docker-compose is to run
docker-compose down. This causes Reactor to stop, but also deletes the container. Any upgrades applied to the container are lost in that instant, because the container is discarded. When you later rundocker-compose up -d, the container is re-created from the (old) image, and will be whatever version that image is. Maybe not a disaster, maybe it is. This could be addressed by retraining docker-compose users to usedocker-compose stoprather thandocker-compose down, but the distinction would need to be taught (and learned) as both are useful, and the infrequency of use of these commands would likely suffer from brain-drain over time (i.e. when to use which and what their side effects could be/will be lost on the user a few months from now). But it's such a subtle distinction that people will shoot themselves in the foot easily and regularly, I fear.Bare-metal is somewhat easier, because at least the process can be assured it's writing on the one and only (relevant) image, in the install directory, so that's a bit of relief. Unfortunately, a lot of people really don't understand Linux file permissions, their relations to users and groups, etc., and routinely goof up the permissions of files all over their system, including in the Reactor install directory. This isn't a problem for them after the first "fix," because thereafter they do the manual upgrades the same way, logged in as the same user (in some cases, even as root, which is a serious no-no), and so it works for them as that user in that case, good enough. But for an automated process running in an unprivileged environment, it can mean that some files aren't writable, and the upgrade only half-happens... the upgrade process crashes, some files are new and some are old, and the Reactor install is basically dead and broken. I can't fix the permissions from the running instance, because it's running as an unprivileged user (well, hopefully; woe unto those who run anything as root). The user then manually applies the upgrade to recover the system, which goes fine because of course he's running the privileged user with the right permissions. A bug/post for the upgrade process then gets reported, and I then spend hours or days going back and forth, digging through the user's 3,000+ files in a typical Reactor install, looking for the broken ones and teaching the user how to fix them. (Permissions and their potential brokenness is also an issue for doing automated backups/restores, since that was mentioned as well.)
Oh, and then there's Windows. I won't even start. I've already written a book (again).
With regard to the suggestion of a standard install method: (a) there is no "one size fits all" — what works for Ubuntu doesn't work for Synology DSM or QNAP, and certainly not for Windows; and (b) the install methods that are recommended are all carefully documented; experience shows that I can write out every detail I can think of, and what actually happens on the user's system is 100% of that or some amount less, or the user has some condition in their system/environment that I could not/did not anticipate that causes problems. My preferred method for most users is docker (and specifically, with docker-compose), because the container strategy removes some of these risks, but that's not always the easiest for their environment (e.g. Synology has docker but no -compose), and the accepted mechanisms for upgrading containers in the docker world in general are ironically exactly the subject of complaints by OP and others here, despite the relative ubiquity and ease of these mechanisms.
The point is, there is no panacaea here. You run these systems, not me. You do things I have no knowledge of, and sometimes those things bite back. The majority of my time supporting this product is troubleshooting your environments, not my code (I'm not saying I'm perfect — I make mistakes and bugs are a reality, but they're not the majority of support issues here in terms of time spent). Anything and everything I do in the system is looked at not just through the lens of whether it's convenient for the user, but very much through the lens of supportability. There are lots of features I get asked to do, and as you've seen (even recently), there are some that I refuse to consider simply because it would make the system less supportable, in my view. As features get added, not only is the usability of the system required to improve, but its quality is expected to improve as well (fewer bugs, better support, etc.) — those are my expectations, which I'm sure you share. If one doesn't consider supportability (and that means both in user support and code maintenance/reliability/scalability), one ends up with a lot of features that nobody asked for, don't work, and aren't usable (I can point you in the direction of such a product as an alternative if you're really interested in that).
There is a running, hidden upgrade process in the current build. I've been experimenting with this for a bit, getting to learn it, and discovering these issues. It's not that I won't consider making it available; I'm still studying it, and pondering the wisdom of it. Maybe sometimes I worry too much about things like this, I don't know. But when it goes wrong, there's nobody but you and me to fix it, and there's a lot of you and only one of me, so as I said in another recent conversation, handing out something that feels like a grenade with no pin sometimes doesn't seem like the best idea to me, and there are probably other things this system needs to do that I can better spend my time on. Maybe this is one of those things.
I'll leave this one up to you guys. If you can tolerate these side effects, I'll release the feature. But know that if you break your install because (docker) you somehow delete the container and recreate it from an old image, or (bare-metal) your install has broken permissions or other issues that the upgrade process can't work through, my answer will be short: that's a risk you accepted, do a clean reinstall from a current image, restore your config/state backup, and start over.
@toggledbits this makes tons of sense why anyone should want an update button mainly Docker users.
In terms of bare metal users, say if a user messed with their files permissions enough that it would cause issues when updating Reactor, wouldn't they run into the same errors even if they manually updated or used the update button? I wouldn't mind an update button for bare metal users, since from your explanation seems like a possible issue with won't come up with the actually update process itself, it can come with something else (like file permissions etc). Meaning that they'd run into these errors even if they manually updated Reactor like we do now.
Not arguing though, its a fairly low level request from me. I can clearly see why an update button for Docker users could be a slow and silent death. As @CatmanV2 for bare metal the update process really only takes 90 seconds ahah.
-
@toggledbits this makes tons of sense why anyone should want an update button mainly Docker users.
In terms of bare metal users, say if a user messed with their files permissions enough that it would cause issues when updating Reactor, wouldn't they run into the same errors even if they manually updated or used the update button? I wouldn't mind an update button for bare metal users, since from your explanation seems like a possible issue with won't come up with the actually update process itself, it can come with something else (like file permissions etc). Meaning that they'd run into these errors even if they manually updated Reactor like we do now.
Not arguing though, its a fairly low level request from me. I can clearly see why an update button for Docker users could be a slow and silent death. As @CatmanV2 for bare metal the update process really only takes 90 seconds ahah.
@pabla said in Quality of Life Request: Update Button:
wouldn't they run into the same errors even if they manually updated or used the update button?
Not necessarily... some users... I've seen it... will run into permission problems and their answer, not understanding the problem or how to fix it, is to use
sudo tar xvfto just lay tracks over everything. This would eliminate the permissions problem unpackaging the archive, but new files may become root-owned, which isn't right but the code doesn't care as long as its readable. If their umask allows world-readable files (and 022 is a common default that does exactly that), the Reactor runtime will never know permissions are broken, because every file it needs is readable without consideration of ownership. The un-tar'ing doesn't touchlogs,config, etc. so any permissions there aren't relevant and aren't changed. And because some of the files are now root-owned that shouldn't be, the permissions problem has been made worse and again, unless they are truly fixed the right way, thensudowill continue to be the only way upgrades will succeed. It perpetuates and exacerbates.I really get how painful the docker upgrades are on Synology. I'm guessing QNAP is probably not much different, and I think several people have been bitten by Portainer oddities regardless of platform.
The process just needs more thought. I could, for example, from the next build onward, prevent the system from starting if the config and data are from a newer version. The problem there is that it needs to be detected early in startup, and if the system can't use the data, it has to exit hard, because it can't run without any data at all, and it can't touch what it has. There would be no UI feedback other than "DISCONNECTED" (i.e. the behavior when Reactor can't start). A "click-to-upgrade" to fix it wouldn't be an option because the UI would not be running, so a manual upgrade would be required at that point. And maybe that's OK? Maybe that's such an extreme/infrequent circumstance that it should be that way? A manual upgrade once in a blue moon may not be so bad... I don't know... looking for feedback... trying to figure it out...
-
I personally do not think the update process on Synology docker is that bad. A few more clicks than an easy button but not horrible. All my other docker containers are updated the same way. I like the docker image though. I am not familiar with the other platforms so I can’t comment on those update processes.
-
 C CatmanV2 referenced this topic on
C CatmanV2 referenced this topic on
-
I too am happy with the current process. Super fast for me. I run everything under Synology/Docker. I no longer have issues upgrading containers such as Reactor, HA, etc. since I switched to Portainer several months ago. So not sure what those "Portainer" oddities are/were. Something I should keep an eye on? Or I have just been lucky?
Synology NAS, Docker, Zooz Z-Wave Stick 700, Z-Wave JS-UI, Reactor, Home Assistant, Grafana, and InfluxDB.
-
I too am happy with the current process. Super fast for me. I run everything under Synology/Docker. I no longer have issues upgrading containers such as Reactor, HA, etc. since I switched to Portainer several months ago. So not sure what those "Portainer" oddities are/were. Something I should keep an eye on? Or I have just been lucky?
-
Some input from a Windows user.
An update button would of course be a nice to have feature, but I also agree with several other here. A "normal" update, aka don't need new dependencies, just take a short moment to install.
Were I usually stumble is when an update of dependencies are needed. That have taken me hours of search-try--error-tryagain before getting that to work sometimes.My dream would be to have a "windows installer" for MSR, that checks dependencies, install a systemservice etc.
Over time I think that would be a safer/more stable way, with fewer user errors.With this said, I can understand really understand that @toggledbits need to handle this "his way" to be able to support differen't enviroments (and users
") )
) -
I don't know if this helps for other Docker users, but not long after I got started with Docker I found Portainer, and I've been running it alongside Reactor and my other containers on my Raspberry Pi 4. With Portainer, there may not be a one-step update button, but I find it makes updates much easier.
I just updated Reactor to the latest. All I had to do was go to the Portainer URL in my browser, then
- Click on the Reactor container in the Containers list
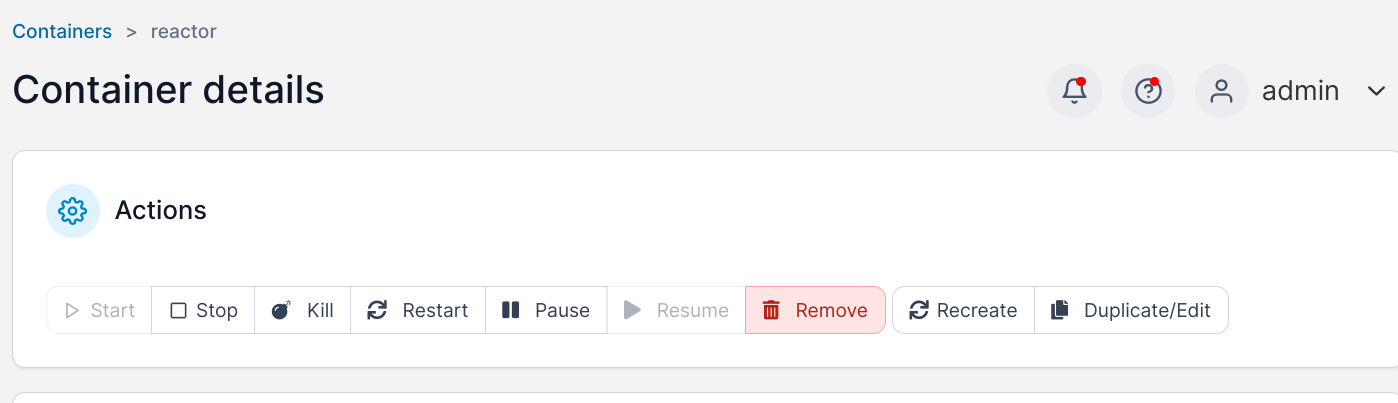
-
Click 'Recreate"
-
Toggle "Always pull new image" on the window that pops up
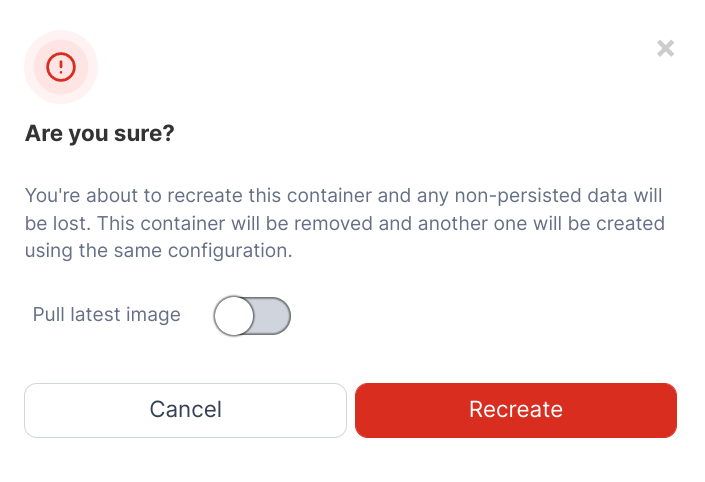
- Click "Recreate"
It isn't one click, but it can be done in a browser tab from any machine with network access to the Docker host. No VNC/SSH into the machine, no Docker commands to run from the command line.
Portainer also has links to view the container logs and to open a command window in the container, which I use all the time. You can also use the "duplicate/edit" button to change or add environment variables while updating, which is how I added the NODE_PATH a few updates back.
-
Thanks for the Portainer explanation, I'm certain I've had a spell cast on me. I'll try again once the Pi400 become available once more.
Lastly, I think the point has been lost, it's about QOL, not about how easy it is to do in another way.
From my perspective if it isn't easy to use by 98% of the public then it's too much trouble and they might look at it then discard it for another solution.
The comments so far are from users who are in the 2% and are happy to tinker. I'm happy for you.
If anyone wants to see how Consumer friendly software should be to set up, then have a look at Homeseer4. Update ...no problem with 1 click. -
Thanks for the Portainer explanation, I'm certain I've had a spell cast on me. I'll try again once the Pi400 become available once more.
Lastly, I think the point has been lost, it's about QOL, not about how easy it is to do in another way.
From my perspective if it isn't easy to use by 98% of the public then it's too much trouble and they might look at it then discard it for another solution.
The comments so far are from users who are in the 2% and are happy to tinker. I'm happy for you.
If anyone wants to see how Consumer friendly software should be to set up, then have a look at Homeseer4. Update ...no problem with 1 click.@black-cat Isn't homeseer a walled garden like Hubitat, Ezlo, etc.? You buy their hub and live within their infrastructure.
That's not MSR. MSR works on various OS/hardware and communicates with multiple hubs.
Whilst I appreciate your POV, it's not apples>apples comparison you're making here.
*Hubitat C-7 2.5.0.159
*Proxmox VE v8, Beelink MiniPC 12GBs, SSD*HAOS
Core 2026.7.2
w/ HA Connect ZWA-2
FW: v1.1
SDK: v7.23.1*Prod MSR in docker/portainer
MSR: latest-26193-8dd8f854
MQTTController: 25139
ZWave Controller: 25139 -
@black-cat Isn't homeseer a walled garden like Hubitat, Ezlo, etc.? You buy their hub and live within their infrastructure.
That's not MSR. MSR works on various OS/hardware and communicates with multiple hubs.
Whilst I appreciate your POV, it's not apples>apples comparison you're making here.
@gwp1 said in Quality of Life Request: Update Button:
You buy their hub and live within their infrastructure.
Nup, you can use any old Laptop or RasPi. Runs on Windows or Lynx. i'd love to promote MSR to Homeseer users but it lacks the simplicity hence the backing of the request.
Realistically, I'm not going to see it happen which is a shame as Patrick has put a lot of time into development for the 2%.aka Zedrally
-
I personally do not think the update process on Synology docker is that bad. A few more clicks than an easy button but not horrible. All my other docker containers are updated the same way. I like the docker image though. I am not familiar with the other platforms so I can’t comment on those update processes.
@sweetgenius I agree, Synology Docker container upgrade process is not too bad.
I frequently keep both MSR and Synology UI open on separate browser tabs and either do a quick upgrade using "reset" or a bit careful upgrade using "duplicate settings" and retaining old container as a backup/rollback option.
Originally I favored a simple update button for MSR, but after Patrick's explanations I realized it's not that simple after all.
-
@gwp1 said in Quality of Life Request: Update Button:
You buy their hub and live within their infrastructure.
Nup, you can use any old Laptop or RasPi. Runs on Windows or Lynx. i'd love to promote MSR to Homeseer users but it lacks the simplicity hence the backing of the request.
Realistically, I'm not going to see it happen which is a shame as Patrick has put a lot of time into development for the 2%.@black-cat Interesting, I guess I missed that it's available as a paid download for install on whatever platform.
-
@gwp1 said in Quality of Life Request: Update Button:
You buy their hub and live within their infrastructure.
Nup, you can use any old Laptop or RasPi. Runs on Windows or Lynx. i'd love to promote MSR to Homeseer users but it lacks the simplicity hence the backing of the request.
Realistically, I'm not going to see it happen which is a shame as Patrick has put a lot of time into development for the 2%.@black-cat said in Quality of Life Request: Update Button:
Realistically, I'm not going to see it happen which is a shame as Patrick has put a lot of time into development for the 2%.
I completely understand this position and I want you (all of you) to understand where I currently stand on this (boy, that's a lot of standing)...
First, I agree that the upgrade issue is important. My long missive wasn't meant to say "not doing it," it was meant to communicate that it's not a simple issue, and isn't one of those features that suddenly appears in the next build after a couple of posts. There are some real issues with usability and stability that have to be taken into account. What I definitely don't want is to have it be a feature that bricks users when they've gotten small parts of the installation wrong, or their system is set up in some weird way. It's a nightmare for the user, obviously, to have their automation suddenly not working, and it's also a nightmare for me to remote-troubleshoot a system where I have no idea what's been done to it, how it got to where it is, what flailing may have happened since it went down, etc. Troubleshooting inside Reactor is hard enough; troubleshooting the rest of the universe around it is not a business I want to be in. I am confident that I can sufficiently engineer, at least for Linux users, a sufficiently robust pre-flight check of the system to reduce the risk of an upgrade going wrong, and that is where a lot of time will be spent. As I said, I already have a running upgrade facility in the recent builds. It does not have the depth of pre-flight that I feel it needs to make me confident that you can be confident in using it... yet.
Backup and restore is a similar issue, although a slightly more contained problem. I already have a running backup facility in the system. What is not there is a UI for restore, and I've mentioned before, very often the UI for things is as much or more code than the feature itself. It's also a lot harder to test, not just because there are multiple browsers that have to be considered, but because the core features of the product are easy to write automated test tools for, while UI testing tends more toward spending screen time.
The real usability issue for me, about which I am most concerned, is none of these, though. The real usability issue for me is settings. I don't want you to have to spend time learning or editing YAML (or JSON). I have long had a plan to write a settings subsystem for the UI. This is an incredibly complex problem to solve, and I've prototyped several approaches and, so far, not been satisfied with the results — it's very easy to back yourself into a corner. It cannot be done without changes in core as well, many of which will have to be evolved into the system over time. Evidence of this complexity can be seen in the Home Assistant world, where their team has literally spent years making the transition from YAML configuration of entities and integrations to UI-based.
I've already read between the lines on this thread, and the backup thread. My current engineering plan is to focus entirely on these three usability issues for the foreseeable future. You will, for some time to come, see a minimum of new core features. I will continue bug-fix and device support updates, but I would guess at this point that you won't see any new major feature upgrades until late Q1 or early Q2 2023. It's going to be a long road. But I believe that the settings issue, in particular, is the real big mover in terms of getting me out of @Black-Cat 's "2%". Adding backup/restore and upgrade will put me on track to an appliance-ready product, which is really my long-term goal.
Core functionality has been the focus for over two years. I agree it's time to make "expert mode" an option, not a requirement.
Author of Multi-system Reactor and Reactor, DelayLight, Switchboard, and about a dozen other plugins that run on Vera and openLuup.
-
@black-cat said in Quality of Life Request: Update Button:
Realistically, I'm not going to see it happen which is a shame as Patrick has put a lot of time into development for the 2%.
I completely understand this position and I want you (all of you) to understand where I currently stand on this (boy, that's a lot of standing)...
First, I agree that the upgrade issue is important. My long missive wasn't meant to say "not doing it," it was meant to communicate that it's not a simple issue, and isn't one of those features that suddenly appears in the next build after a couple of posts. There are some real issues with usability and stability that have to be taken into account. What I definitely don't want is to have it be a feature that bricks users when they've gotten small parts of the installation wrong, or their system is set up in some weird way. It's a nightmare for the user, obviously, to have their automation suddenly not working, and it's also a nightmare for me to remote-troubleshoot a system where I have no idea what's been done to it, how it got to where it is, what flailing may have happened since it went down, etc. Troubleshooting inside Reactor is hard enough; troubleshooting the rest of the universe around it is not a business I want to be in. I am confident that I can sufficiently engineer, at least for Linux users, a sufficiently robust pre-flight check of the system to reduce the risk of an upgrade going wrong, and that is where a lot of time will be spent. As I said, I already have a running upgrade facility in the recent builds. It does not have the depth of pre-flight that I feel it needs to make me confident that you can be confident in using it... yet.
Backup and restore is a similar issue, although a slightly more contained problem. I already have a running backup facility in the system. What is not there is a UI for restore, and I've mentioned before, very often the UI for things is as much or more code than the feature itself. It's also a lot harder to test, not just because there are multiple browsers that have to be considered, but because the core features of the product are easy to write automated test tools for, while UI testing tends more toward spending screen time.
The real usability issue for me, about which I am most concerned, is none of these, though. The real usability issue for me is settings. I don't want you to have to spend time learning or editing YAML (or JSON). I have long had a plan to write a settings subsystem for the UI. This is an incredibly complex problem to solve, and I've prototyped several approaches and, so far, not been satisfied with the results — it's very easy to back yourself into a corner. It cannot be done without changes in core as well, many of which will have to be evolved into the system over time. Evidence of this complexity can be seen in the Home Assistant world, where their team has literally spent years making the transition from YAML configuration of entities and integrations to UI-based.
I've already read between the lines on this thread, and the backup thread. My current engineering plan is to focus entirely on these three usability issues for the foreseeable future. You will, for some time to come, see a minimum of new core features. I will continue bug-fix and device support updates, but I would guess at this point that you won't see any new major feature upgrades until late Q1 or early Q2 2023. It's going to be a long road. But I believe that the settings issue, in particular, is the real big mover in terms of getting me out of @Black-Cat 's "2%". Adding backup/restore and upgrade will put me on track to an appliance-ready product, which is really my long-term goal.
Core functionality has been the focus for over two years. I agree it's time to make "expert mode" an option, not a requirement.
@toggledbits I have a small script running in background to update msr via docker, at my command, when I'm outside and I don't want to ssh into the machine. I for one will love a flag or similar to know a new version is available and do my own thing. I've not looked at the entities, to be honest.
Semplification (such as automatic device discovery and a click to add to the engine) is what will make a huge difference for the average brother in-law trying to lightly automate stuff - I agree.
--
On a mission to automate everything. -
@toggledbits I have a small script running in background to update msr via docker, at my command, when I'm outside and I don't want to ssh into the machine. I for one will love a flag or similar to know a new version is available and do my own thing. I've not looked at the entities, to be honest.
Semplification (such as automatic device discovery and a click to add to the engine) is what will make a huge difference for the average brother in-law trying to lightly automate stuff - I agree.
@therealdb said in Quality of Life Request: Update Button:
I for one will love a flag or similar to know a new version is available and do my own thing. I've not looked at the entities, to be honest.
Check out the
reactor_system.update_availableattribute on the Reactor System (reactor_system>system) entity. -
@therealdb said in Quality of Life Request: Update Button:
I for one will love a flag or similar to know a new version is available and do my own thing. I've not looked at the entities, to be honest.
Check out the
reactor_system.update_availableattribute on the Reactor System (reactor_system>system) entity.@toggledbits @therealdb I've used this to create a Pushover notification to my watch. This also surfaces in the
Current Alertspane.*Hubitat C-7 2.5.0.159
*Proxmox VE v8, Beelink MiniPC 12GBs, SSD*HAOS
Core 2026.7.2
w/ HA Connect ZWA-2
FW: v1.1
SDK: v7.23.1*Prod MSR in docker/portainer
MSR: latest-26193-8dd8f854
MQTTController: 25139
ZWave Controller: 25139