Need Testers
-
@tunnus If your specific concern is the Timer messages, don't be concerned. Long story shortened: these Timer objects were originally used for long intervals and the warning was put in place to help identify bugs in computing the length of those intervals, but they ended up being used for short intervals, too, and there are some conditions where those intervals can randomly be so short that they trigger the warning. I think it's time for this warning to be relegated to debug level or removed.
You clearly have something that's logging a lot, and that's causing frequent log rotations. This not only wastes time/cycles and bytes on the disk, but it also makes debugging anything on your system harder for the reason you stated: you can't find the errors, likely because (a) it's logging too much (you're sipping from a firehose), and (b) it's rotating so frequently that you're losing useful data quickly.
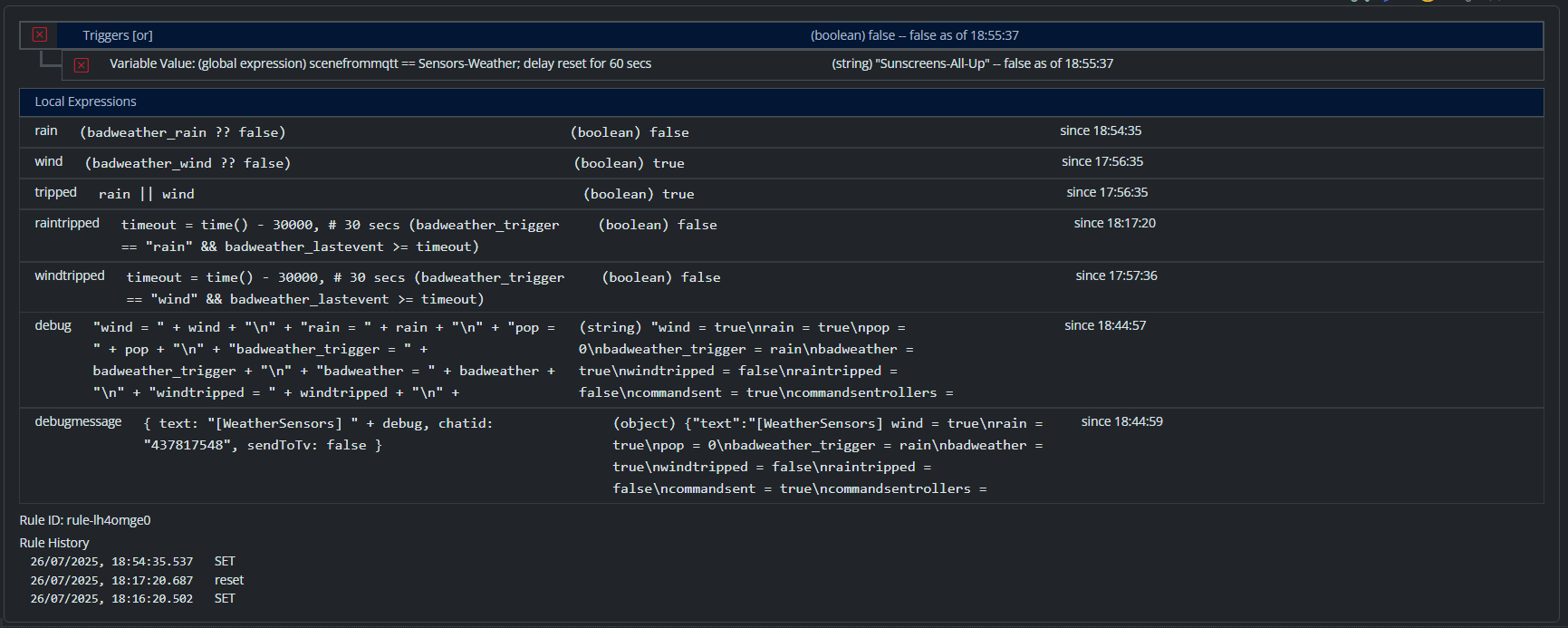
What I'd suggest is that you identify the affected rules (i.e. those that are responding to the frequent entity attribute changes), and increase their specific log levels to reduce the log output. You can do that for an individual rule. You need to get the rule ID, which you can derive from the UI by opening the rule's state in the list. You can also see it logged. Let's pick on
rule-ktmrcd6d... we modifyconfig/logging.yamlby adding the following:# The line below is indented two spaces; the line after is indented four spaces. "Rule#rule-ktmrcd6d": level: 3This puts the logging minimum level at "NOTICE", so all of the INFO messages associated with rule evaluation will be suppressed for that rule only (other rules will not be affected). That should considerably reduce your log traffic.
I saw your question about the frequent updates as it relates to InfluxDB, and that's a sticky business. I'll respond to that over there.
Author of Multi-system Reactor and Reactor, DelayLight, Switchboard, and about a dozen other plugins that run on Vera and openLuup.
-
@tunnus If your specific concern is the Timer messages, don't be concerned. Long story shortened: these Timer objects were originally used for long intervals and the warning was put in place to help identify bugs in computing the length of those intervals, but they ended up being used for short intervals, too, and there are some conditions where those intervals can randomly be so short that they trigger the warning. I think it's time for this warning to be relegated to debug level or removed.
You clearly have something that's logging a lot, and that's causing frequent log rotations. This not only wastes time/cycles and bytes on the disk, but it also makes debugging anything on your system harder for the reason you stated: you can't find the errors, likely because (a) it's logging too much (you're sipping from a firehose), and (b) it's rotating so frequently that you're losing useful data quickly.
What I'd suggest is that you identify the affected rules (i.e. those that are responding to the frequent entity attribute changes), and increase their specific log levels to reduce the log output. You can do that for an individual rule. You need to get the rule ID, which you can derive from the UI by opening the rule's state in the list. You can also see it logged. Let's pick on
rule-ktmrcd6d... we modifyconfig/logging.yamlby adding the following:# The line below is indented two spaces; the line after is indented four spaces. "Rule#rule-ktmrcd6d": level: 3This puts the logging minimum level at "NOTICE", so all of the INFO messages associated with rule evaluation will be suppressed for that rule only (other rules will not be affected). That should considerably reduce your log traffic.
I saw your question about the frequent updates as it relates to InfluxDB, and that's a sticky business. I'll respond to that over there.
-
@tunnus If your specific concern is the Timer messages, don't be concerned. Long story shortened: these Timer objects were originally used for long intervals and the warning was put in place to help identify bugs in computing the length of those intervals, but they ended up being used for short intervals, too, and there are some conditions where those intervals can randomly be so short that they trigger the warning. I think it's time for this warning to be relegated to debug level or removed.
You clearly have something that's logging a lot, and that's causing frequent log rotations. This not only wastes time/cycles and bytes on the disk, but it also makes debugging anything on your system harder for the reason you stated: you can't find the errors, likely because (a) it's logging too much (you're sipping from a firehose), and (b) it's rotating so frequently that you're losing useful data quickly.
What I'd suggest is that you identify the affected rules (i.e. those that are responding to the frequent entity attribute changes), and increase their specific log levels to reduce the log output. You can do that for an individual rule. You need to get the rule ID, which you can derive from the UI by opening the rule's state in the list. You can also see it logged. Let's pick on
rule-ktmrcd6d... we modifyconfig/logging.yamlby adding the following:# The line below is indented two spaces; the line after is indented four spaces. "Rule#rule-ktmrcd6d": level: 3This puts the logging minimum level at "NOTICE", so all of the INFO messages associated with rule evaluation will be suppressed for that rule only (other rules will not be affected). That should considerably reduce your log traffic.
I saw your question about the frequent updates as it relates to InfluxDB, and that's a sticky business. I'll respond to that over there.
@toggledbits thanks for the tip, now logging traffic is considerably slower (log rotation ca. 10 minutes)
-
userauth build 24137
- Updated the documentation theme and its supporting plugins; improved the appearance of code snippets with syntax highlighting in most cases; add line highlighting in many code snippets to draw attention to certain elements or changes.
- Dashboard: added new Thermostat type (supported by Level.updown layout) for capabilities hvac_heating_unit/hvac_cooling_unit. Evolving; further improvements coming.
- VirtualEntityController: Support for time-series data collection and aggregation. See the docs). As of this build, not all aggregators have been tested.
- Remove spurious debug warning about short timers.
- Fix detection of local docs and handling of static HTML files in the local installation.
- HassController: Bless Hass to 2024.5.3
Author of Multi-system Reactor and Reactor, DelayLight, Switchboard, and about a dozen other plugins that run on Vera and openLuup.
-
userauth build 24137
- Updated the documentation theme and its supporting plugins; improved the appearance of code snippets with syntax highlighting in most cases; add line highlighting in many code snippets to draw attention to certain elements or changes.
- Dashboard: added new Thermostat type (supported by Level.updown layout) for capabilities hvac_heating_unit/hvac_cooling_unit. Evolving; further improvements coming.
- VirtualEntityController: Support for time-series data collection and aggregation. See the docs). As of this build, not all aggregators have been tested.
- Remove spurious debug warning about short timers.
- Fix detection of local docs and handling of static HTML files in the local installation.
- HassController: Bless Hass to 2024.5.3
@toggledbits thanks, can confirm that (local) manual is fixed now, no more "initializing search"
-
@toggledbits I think the
restart reactorbutton is down again. When I click it I'm pushed back to the user login screen and immediately login to see the Status screen loading normally... not showingDisconnectedas it usually does as it restarts. Logs provided in Dropbox. -
Does it do that every time you use it?
-
Does it do that every time you use it?
@toggledbits Yessir.
-
OK. That's normal behavior if the login/session cookie expires or is no longer valid. And it's all browser-side, so the logs aren't of any value there. And it's working for me, so we may have to dig a little. Next time you are tempted to use the Restart button, just do a plain refresh on your browser and see (report) what happens.
Also, what browser are you using? And, please upload your users.yaml file (redact any plaintext passwords)
-
OK. That's normal behavior if the login/session cookie expires or is no longer valid. And it's all browser-side, so the logs aren't of any value there. And it's working for me, so we may have to dig a little. Next time you are tempted to use the Restart button, just do a plain refresh on your browser and see (report) what happens.
Also, what browser are you using? And, please upload your users.yaml file (redact any plaintext passwords)
@toggledbits Using Brave browser. Redacted
users.yamlon it's way. -
If you just refresh the page instead of hitting the button, does it refresh, or go to the login page?
-
userauth build 24143
- Fixes something that might, perhaps, address the Restart button issue some people are having (and I cannot reproduce at all on any broser). Also adds some debug (browser side) that we might be able to access to figure it out if it persists.
- Revamps the port determination. Some of you, particularly docker users, may find that your Reactor UI shifts to port 8554, and is actually the desired location for HTTPS service.
- Updated a lot of docs, including developer docs for building controllers.
Author of Multi-system Reactor and Reactor, DelayLight, Switchboard, and about a dozen other plugins that run on Vera and openLuup.
-
userauth build 24143
- Fixes something that might, perhaps, address the Restart button issue some people are having (and I cannot reproduce at all on any broser). Also adds some debug (browser side) that we might be able to access to figure it out if it persists.
- Revamps the port determination. Some of you, particularly docker users, may find that your Reactor UI shifts to port 8554, and is actually the desired location for HTTPS service.
- Updated a lot of docs, including developer docs for building controllers.
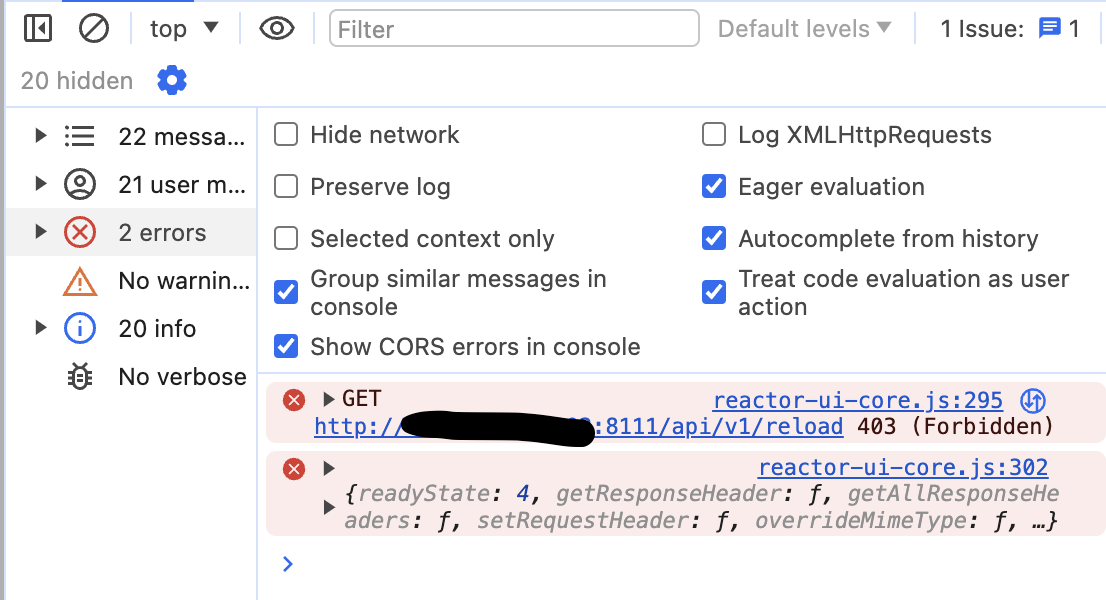
@toggledbits Restart-button still does not work. Chrome:
-
That's ACL restriction. You probably need to give logged-in users permission to use the API, or at least, that particular API.
Author of Multi-system Reactor and Reactor, DelayLight, Switchboard, and about a dozen other plugins that run on Vera and openLuup.
-
That's ACL restriction. You probably need to give logged-in users permission to use the API, or at least, that particular API.
@toggledbits here's my users.yaml: (how should I change that?)
users: # This section defines your valid users. The format is: # username: password (one per line). admin: xxxxxxxx groups: admin: users: - admin applications: true # special form allows access to ALL applications api: default: allow session: timeout: 43200 rolling: true # activity extends timeout when true # If log_acls is true, the selected ACL for every API access is logged. log_acls: true # If debug_acls is true, even more information about ACL selection is logged. debug_acls: false -
That's not up to date with current usage/structure. Refer to the
users.yamlfile that came in thedist-configdirectory, and the documentation for Access Control.Author of Multi-system Reactor and Reactor, DelayLight, Switchboard, and about a dozen other plugins that run on Vera and openLuup.
-
That's not up to date with current usage/structure. Refer to the
users.yamlfile that came in thedist-configdirectory, and the documentation for Access Control.@toggledbits ok, using that new file as a reference, now Restart-button is working
-
userauth build 24145
- Fix issue with VirtualEntityController weighted average computation (remove workarounds if you added them per earlier post).
- Make login page react to ENTER key.
- Remove dependency on user-supplied ACL for certain functions in the UI, like the Restart Reactor button on the Tools tab. These functions are now performed through the websocket interface.
If there are no further issues, this build will likely be the last on this branch, and I will be merging all the changes into
latestand releasing that over the weekend or sometime next week.Author of Multi-system Reactor and Reactor, DelayLight, Switchboard, and about a dozen other plugins that run on Vera and openLuup.
