CCTV on Openluup
-
It's all there...
I_openLuupCamera1.xml implementation file:
A camera device created with this implementation file will create an associated child Motion Sensor device which is triggered when the camera’s own motion detection algorithm sends an email.
Configuration:
Out of the box, openLuup will start the SMTP server on port 2525. This can be changed in Lua Startup code with the following line:
luup.attr_set ("openLuup.SMTP.Port", 1234) -- use port 1234 insteadThe camera’s device implementation file may be set on the openLuup device’s Attributes page, followed by a Luup reload. The only other significant parameters are the usual:
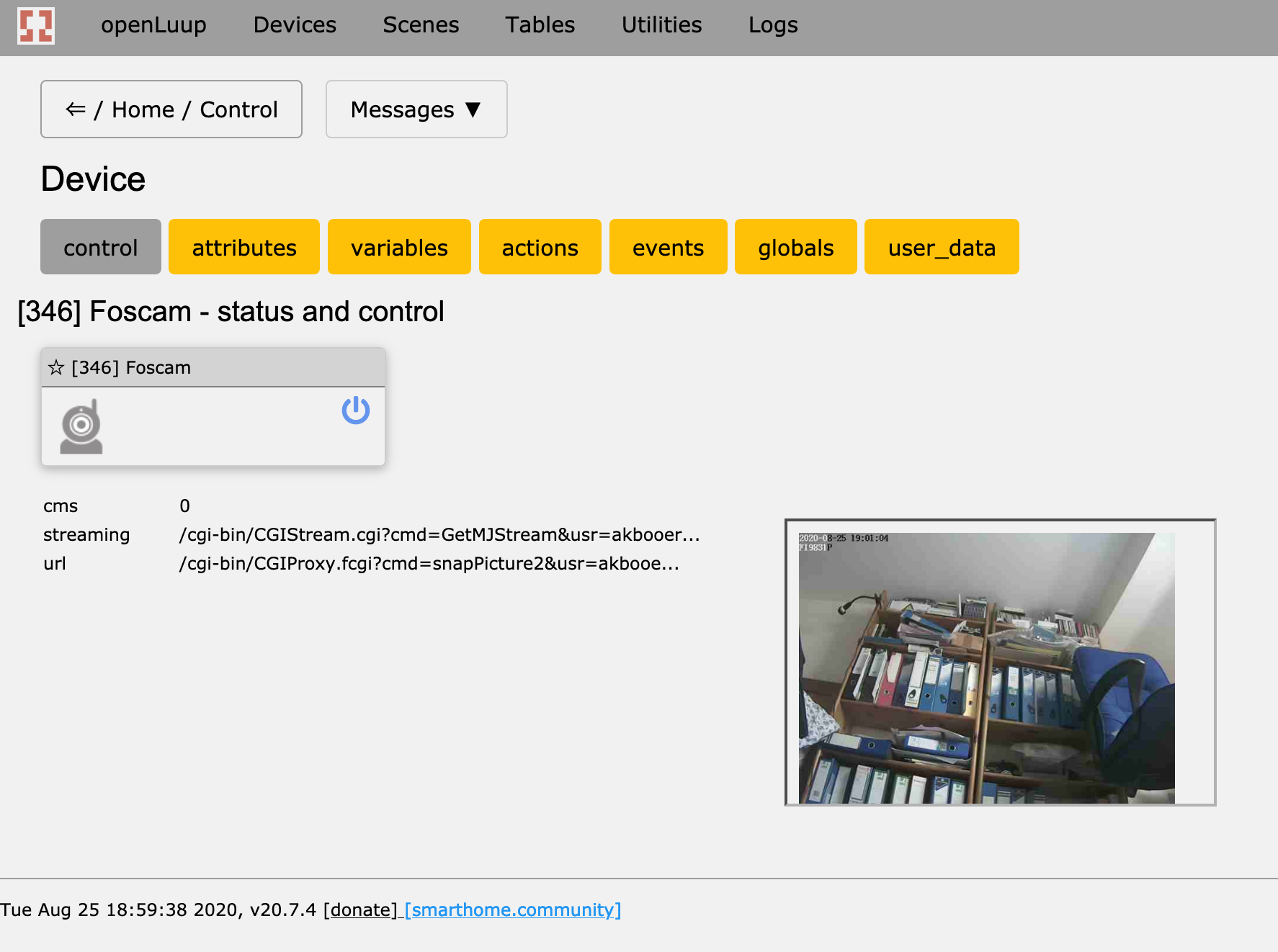
ipattribute, and theURLandDirectStreamingURLdevice variables.Camera configuration is obviously device-specific. For my Foscam camera the important parameters are:
- Enable - ticked
- SMTP Server - the IP address of openLuup on your LAN eg. 172.16.42.156
- SMTP Port - 2525, or whatever other port number you configured in openLuup startup
- Need Authentication - No
- SMTP Username / Password - not used
- Sender Email - must include the form
xxx@yyy, for exampleFoscam@Study.local - First Receiver -
openLuup@openLuup.local
My camera (FI9831P) also sends three snapshots as email attachments. These may be ignored, or can be written to a folder accessible from openLuup, depending on the configured email address for the trigger.
The Motion Sensor device will remain triggered for 30 seconds (or longer if the camera is re-triggered within that time.) In keeping with the latest security sensor service file, in addition to the
Trippedvariable, there is also anArmedTrippedvariable which is only set/reset when the device is armed. This makes AltUI device watch triggers easy to write when wanting only to respond when the device is actually armed.