
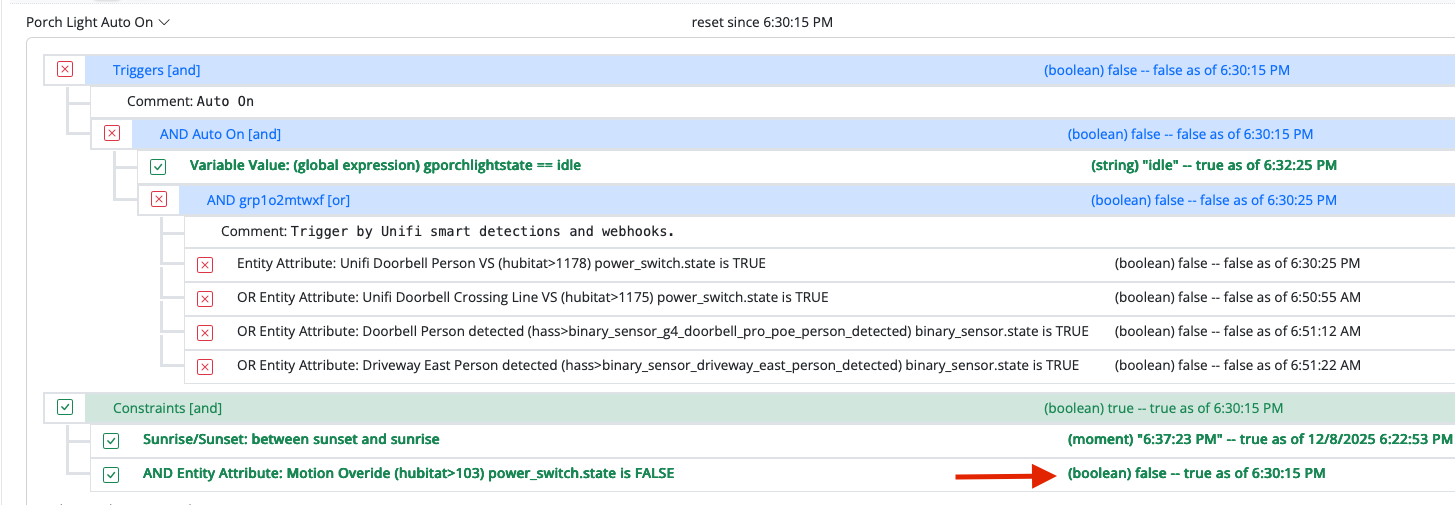




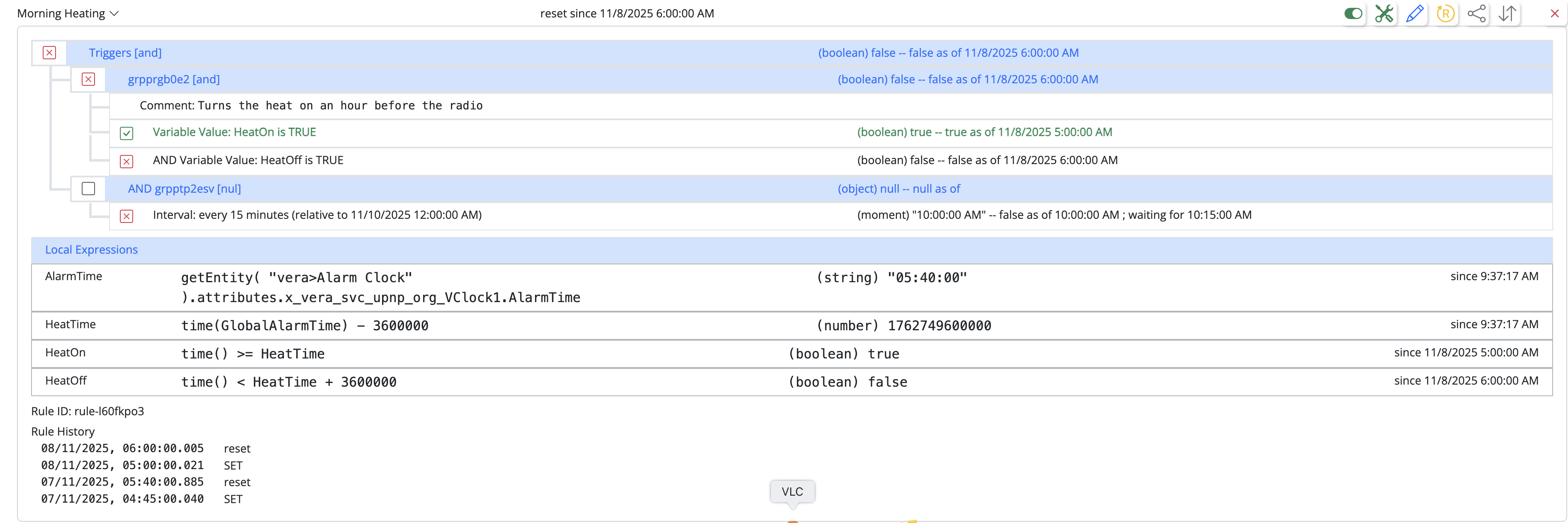


Urgent Help MSR stopped running
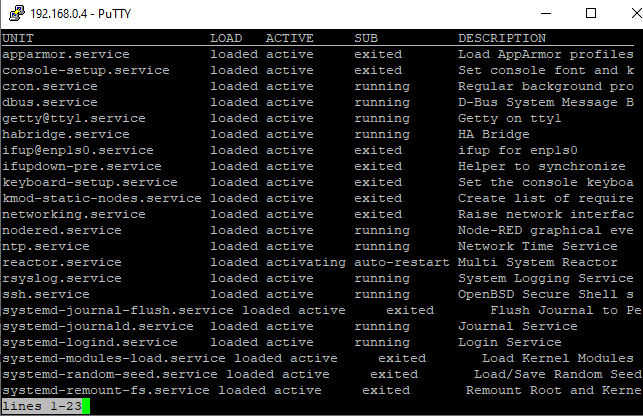
-
@cw-kid it's the folder called
storagein your Reactor folder.Is that the folder with the rulesets in it ?
I have a backup of all the folders and files, but it's not very recent.Hope I am not going to lose the more recent changes to the rules.
-
-
That's good sleuthing and good work. Yes, the
statesfolder gets most of the I/O. If it looks like everything else is intact, that's fine. Rules and rule sets would only be damaged if you happened to edit them during the time the disk was full.On the Reactor master device, there are flags for warning you when disk space is becoming limited; rules with notifications may be a good idea, to avoid future unpleasant surprises.
-
I am assuming I have had a lucky escape here then, all my rules look to be present still, I am assuming "States" is just that as the name suggests the current state of the rules and that they will rebuild and repopulate themselves.
I didn't have any auto backup in place as not really sure how to do that in Linux command line, so I was just now and again manually copying the entire contents of the /reactor folder down on to my PC.
-
All correct.
-
In Entities under Reactor System I have all this information
reactor_system.alert_count=0 reactor_system.alert_last=1647657325518 reactor_system.alert_severity=null reactor_system.alerts=[] reactor_system.arch="x64" reactor_system.hostname="HP-Thin01" reactor_system.internet_ok=null reactor_system.platform="linux" reactor_system.reactor_memory_used=138702848 reactor_system.reactor_uptime=1082 reactor_system.system_load=[0.13,0.15,0.11] reactor_system.system_memory_free=2020356096 reactor_system.system_memory_size=3537993728 reactor_system.system_uptime=17002.98 reactor_system.volume_critical_reactor_base=false reactor_system.volume_critical_reactor_data=false reactor_system.volume_critical_reactor_logs=false reactor_system.volume_reactor_base=[5390756,13825496,0.389,"/home/stuart/reactor"] reactor_system.volume_reactor_data=[5390756,13825496,0.389,"/home/stuart/reactor/storage"] reactor_system.volume_reactor_logs=[5390756,13825496,0.389,"/home/stuart/reactor/logs"] sys_system.state=true Capabilities: reactor_system, sys_system Actions: reactor_system.clear_alert, reactor_system.clear_alerts, sys_system.restartMemory free is that disk or RAM ?
-
-
Losing state will cause rules to possibly run unexpectedly. For example, say you had a rule that triggers between sunrise and sunset. If state was lost due to disk full corruption such as this in mid-day, discarding the state at restart will cause the rule to have no state, therefore think it has a transition into the sunrise (triggered) period and fire. This may or may not be a desirable side-effect, depending entirely on how the user determines the rules to work, and I cannot predetermine whether re-running a rule would have side-effects in the user environment or not. Since this can occur unattended (such as while on vacation or at a remote vacation home), it's potentially very troublesome and should at least be corrected with the full awareness of the user, as you have in this case.
My number one recommendation is that you manage filesystem space well on the system. This is always an issue on all systems, and in Linux/Unix systems in particular, processes can die (due to errors) and files can become (logically) corrupt due to disk full conditions. It is something that needs to be managed. In your case, I would remember what log files were deleted, and investigate why those were so large and not being rotated and expired or archived. In your case, it appears you have a single root volume with everything on it. That means any subsystem running on the box can potentially fill the filesystem and cause other applications to misbehave. Best practices for system management often call for segmenting files/directories out. It is not uncommon, for example, to have
/var,/usrand/homeall on separate filesystems, that any one of them filling (/varoften has this issue because it holds system logs and other fast-changing files) would not result in other files in the other directories to become corrupt or truncated. Taking this to an extreme, but if hardening Reactor is mission-critical to you, it is possible to create a small volume and mount it as/var/reactorat boot time, and use that as the home for thestoragedirectory (andconfig, but not Reactor'slogs), thereby isolating and protecting Reactor's storage from everything else. This is all Linux system management stuff, so not really appropriate to deep dive into, but if you're going to use and maintain these systems as part of your infrastructure, well worth spending the time to learn. A must really, because when it goes wrong, and it will go wrong, your fluency in system management will directly determine the time it takes to recover, and how well (or not) you recover.I can take more mitigating steps to harden startup, and I will definitely do that. I will also see about adding Status page alerts for disk space problems. The way Reactor works, if the disk space problem is mitigated before a restart of Reactor (i.e. while Reactor is running), Reactor will (eventually) rewrite the files with state (which is cached in RAM during operation) -- at shutdown, Reactor writes the RAM state back to disk as a final assurance that they are in sync, just for this reason. But I cannot protect those files from every eventuality, and every other subsystem on the machine works pretty much the same way (rebooting after fixing a no-space condition is always recommended, because many daemons will just die when they can't write a file).
And as I've said again and again and again, please read the documentation and look at your log files. If you see something in the log files that points to obvious issue, handle it. If you don't know how to handle it, post the log file snippet and remember that context is vital, so posting 2-3 lines of a log file may provide little or no useful information (even when the error contains module names and line numbers); it often takes a dozen or more lines of context prior to really interpret how the system got to the crash point, so you must post a least a dozen or more lines prior to any error message you are inquiring about. Fortunately in this case, it was pretty obvious.
Pardon errors. Tapping this out on a bluetooth keyboard and over my home VPN on sketchy Internet made this a bit of a chore. Onward.
-
 T toggledbits locked this topic on
T toggledbits locked this topic on
 SystemController - Reactor - Multi-Hub Automation
SystemController - Reactor - Multi-Hub Automation