



Added IP camera to Ezlo, what is causing this
-
@toggledbits I added an IP camera to my Ezlo for testing and my global variable for Ezlo devices that are not responding randomly do a quick toggle from empty to "IP camera" then back to empty.
Is it the controller interface not supporting IP cameras or something else causing this?
@2021-10-19T23:24:07.826Z[latest-21292]2021-10-19T23:10:00.043Z <Engine:NOTICE> Resuming reaction Schema - Dräneringspump<SET> (rule-ktd8obiy:S) from step 2 [latest-21292]2021-10-19T23:10:00.043Z <Engine:5:Engine.js:1504> Engine#1 reaction rule-ktd8obiy:S step 2 perform { "entity": "vera>device_53", "action": "power_switch.off" } [latest-21292]2021-10-19T23:10:00.043Z <Engine:5:Engine.js:1407> _process_reaction_queue() task returned, new status 3; task 29 [latest-21292]2021-10-19T23:10:00.044Z <VeraController:null> VeraController#vera enqueue task for Entity#vera>device_53 action power_switch.off: task { "newTargetValue": "0", "DeviceNum": 53, "id": "action", "serviceId": "urn:upnp-org:serviceId:SwitchPower1", "action": "SetTarget" } [latest-21292]2021-10-19T23:10:00.044Z <Engine:5:Engine.js:1442> _process_reaction_queue ending with 1 in queue; none delayed/ready; waiting [latest-21292]2021-10-19T23:10:00.048Z <Engine:5:Engine.js:1442> _process_reaction_queue() wake-up! [latest-21292]2021-10-19T23:10:00.049Z <Engine:5:Engine.js:1403> _process_reaction_queue() running task 29 { "tid": 29, "id": "rule-ktd8obiy:S", "rule": "rule-ktd8obiy", "__reaction": [RuleReaction#rule-ktd8obiy:S], "next_step": 3, "status": 1, "ts": 1634684400015, "parent": --null--, "__resolve": --function--, "__reject": --function--, "__promise": [object Promise], "attempts": 3 } [latest-21292]2021-10-19T23:10:00.049Z <Engine:NOTICE> Resuming reaction Schema - Dräneringspump<SET> (rule-ktd8obiy:S) from step 3 [latest-21292]2021-10-19T23:10:00.049Z <Engine:INFO> Schema - Dräneringspump<SET> all actions completed. [latest-21292]2021-10-19T23:10:00.049Z <Engine:5:Engine.js:1407> _process_reaction_queue() task returned, new status -1; task 29 [latest-21292]2021-10-19T23:10:00.050Z <Engine:5:Engine.js:1442> _process_reaction_queue ending with 0 in queue; none delayed/ready; waiting [latest-21292]2021-10-19T23:17:00.724Z <VeraController:ERR> VeraController#vera update request failed: FetchError: network timeout at: http://127.0.0.1:3480/data_request?id=status&DataVersion=574966431&Timeout=15&MinimumDelay=100&output_format=json&_r=1634685402721 [latest-21292]2021-10-19T23:24:07.826Z <EzloController:WARN> EzloController#ezlo warning: update parameter serviceNotification for Entity#ezlo>device_615e11a7129e071220cb5f8d not previously defined! (value now (boolean)false) [latest-21292]2021-10-19T23:24:07.826Z <EzloController:WARN> EzloController#ezlo warning: update parameter syncNotification for Entity#ezlo>device_615e11a7129e071220cb5f8d not previously defined! (value now (boolean)false) [latest-21292]2021-10-19T23:24:07.828Z <Rule:INFO> Rule#rule-ku32xyj5 evaluation in progress; waiting for completion [latest-21292]2021-10-19T23:24:07.828Z <Rule:INFO> Rule#rule-kue8adhf evaluation in progress; waiting for completion [latest-21292]2021-10-19T23:24:07.828Z <Engine:5:Engine.js:981> Engine#1 set global EzloDevicesNotResponding; value=(string)IP Camera [latest-21292]2021-10-19T23:24:12.474Z <Rule:INFO> Rule#rule-ku32xyj5 evaluation in progress; waiting for completion [latest-21292]2021-10-19T23:24:12.475Z <Rule:INFO> Rule#rule-kue8adhf evaluation in progress; waiting for completion [latest-21292]2021-10-19T23:24:12.476Z <Engine:5:Engine.js:981> Engine#1 set global EzloDevicesNotResponding; value=(string) [latest-21292]2021-10-19T23:24:12.482Z <Rule:INFO> Notifiering - Ezlo devices OK (Rule#rule-kue8adhf) SET! [latest-21292]2021-10-19T23:24:12.483Z <Engine:5:Engine.js:1442> _process_reaction_queue() wake-up! [latest-21292]2021-10-19T23:24:12.487Z <Rule:INFO> Notifiering - Ezlo devices OK (Rule#rule-kue8adhf) RESET! -
I need a more complete picture than this. Show the rule(s) involved and the global variables, please. There is a rule toggling at the end of the log snippet, but since you haven't really given me any context to know what is what, what it's doing or not doing, and why, I have no context for what I'm looking at.
And actually, now that I look at it, am I even looking at the rules, or are you just asking about the two log entries at the timestamp you gave? Not clear what your question/problem is....?
Author of Multi-system Reactor and Reactor, DelayLight, Switchboard, and about a dozen other plugins that run on Vera and openLuup.
-
I need a more complete picture than this. Show the rule(s) involved and the global variables, please. There is a rule toggling at the end of the log snippet, but since you haven't really given me any context to know what is what, what it's doing or not doing, and why, I have no context for what I'm looking at.
And actually, now that I look at it, am I even looking at the rules, or are you just asking about the two log entries at the timestamp you gave? Not clear what your question/problem is....?
@toggledbits Sorry for not giving the whole picture. My question is if you know why "IP Camera" is added and removed from the variable within seconds.
Looking at it further myself though it seems like the Ezlo actually is reporting this device as "not reachable" for a few seconds, I misread the log and thought it was within ms and the WARN of "not previously defined" made me curious.The rule is just sending me a notification and triggers if the variable changes from anything to anything AND variable == string"", Pulse for 1 second.
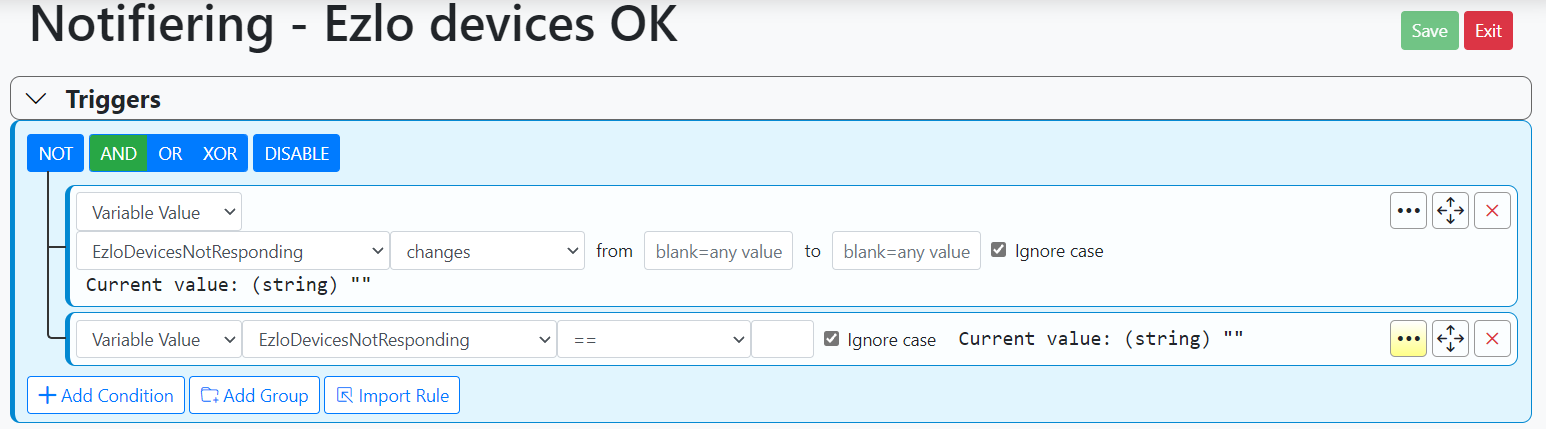
The global expression is

Sorry to bother unnecessary
")
I guess I'll just remove the camera or filter it out in the expression as it's sending me notifications that all devices are responding again when my other rule that notifies me of devices not responding haven't had the chance to pick up the quick toggle. -
The logs are showing that the eZLO is sending updates, and apparently that value changed state twice in about 5 seconds: you can see at 24:07 where the global variable changes, so it has gotten one update and handled it, and then at 24:12 it has gotten another and changed it back. It would be an eZLO-side mystery to unravel why it's sending not-reachable followed by reachable so quickly, maybe a bug in their firmware, maybe just the way it works. It seems possible, even likely, that during any restart of the hub, devices would be marked down until they are known up, and some will just be left in the last known state until a new state is established, and given that the Vera engineering team is still present for the eZLO firmware, I'm sure they are still up to their old tricks and there is some inconsistency in which is chosen for which device or device class/type. I would not be at all surprised if IP-driven devices (like cameras) are marked for failure immediately when any request to the device fails, even on the first try, so lapses in network/wifi or the camera itself may lead to spurious marking of the device as failed followed by a quick recovery. These are all very real risks of the problem being solved.
So, probably something to mention in the other thread on this general (device error) subject: you may need to add a "sustained for" to your rule to dampen response, to allow for such momentary lapses, which are probably more common than we've ever realized, but will be on full display now that people are implementing rules like this.
The logged warnings... since eZLO is such a great unfinished unknown, and there are many inconsistencies and undocumented behaviors of their system and API, when an update for a device from the API arrives with a value that was not in the first device inventory, the warning is issued. Reactor then just adds the value to the device and carries on as if it was always there. So that's largely debug/notice of a surprise, but nothing harmful. And I'm not sure the values involved are even documented; I'll have to look (
serviceNotificationis known according to the API docs, and seems to be an internal value;syncNotificationis undocumented). But in any case, the warnings are advisory only and harmless and irrelevant to behavior here.Thanks for posting the screen shots in English!
Author of Multi-system Reactor and Reactor, DelayLight, Switchboard, and about a dozen other plugins that run on Vera and openLuup.
-
The logs are showing that the eZLO is sending updates, and apparently that value changed state twice in about 5 seconds: you can see at 24:07 where the global variable changes, so it has gotten one update and handled it, and then at 24:12 it has gotten another and changed it back. It would be an eZLO-side mystery to unravel why it's sending not-reachable followed by reachable so quickly, maybe a bug in their firmware, maybe just the way it works. It seems possible, even likely, that during any restart of the hub, devices would be marked down until they are known up, and some will just be left in the last known state until a new state is established, and given that the Vera engineering team is still present for the eZLO firmware, I'm sure they are still up to their old tricks and there is some inconsistency in which is chosen for which device or device class/type. I would not be at all surprised if IP-driven devices (like cameras) are marked for failure immediately when any request to the device fails, even on the first try, so lapses in network/wifi or the camera itself may lead to spurious marking of the device as failed followed by a quick recovery. These are all very real risks of the problem being solved.
So, probably something to mention in the other thread on this general (device error) subject: you may need to add a "sustained for" to your rule to dampen response, to allow for such momentary lapses, which are probably more common than we've ever realized, but will be on full display now that people are implementing rules like this.
The logged warnings... since eZLO is such a great unfinished unknown, and there are many inconsistencies and undocumented behaviors of their system and API, when an update for a device from the API arrives with a value that was not in the first device inventory, the warning is issued. Reactor then just adds the value to the device and carries on as if it was always there. So that's largely debug/notice of a surprise, but nothing harmful. And I'm not sure the values involved are even documented; I'll have to look (
serviceNotificationis known according to the API docs, and seems to be an internal value;syncNotificationis undocumented). But in any case, the warnings are advisory only and harmless and irrelevant to behavior here.Thanks for posting the screen shots in English!
@toggledbits Sustained for is the way to go here, thank you for your advice.
I can say that for Zigbee devices their firmware is a mess, a reboot of the controller marks all devices unreachable until they are physically toggled or reporting new sensor values, so rebooting means going around the house like a fool toggling lights and blowing on temp/humidity sensors, and if you don't do it fast enough you have to reboot again to give the devices a new chance to phone home in time.
-
 T toggledbits locked this topic on
T toggledbits locked this topic on