



Parsing the output of http request
-
I'd like to extract a specific part of a response to http request, in this case of link https://www.nibeuplink.com/Welcome#service_message. If there's something in "service_message" I'd store it & send using Telegram.
I reckon I'd have to use something similar as in this thread?
-
Can't see any data on that link without an account, but you're right about the thread. That's the way.
Author of Multi-system Reactor and Reactor, DelayLight, Switchboard, and about a dozen other plugins that run on Vera and openLuup.
-
Can't see any data on that link without an account, but you're right about the thread. That's the way.
@toggledbits actually to see this message (which is still active as the time of writing this) you do not have to login, it's a public page (there's a orange box with text "Service Status" - though it could go away soon)
-
Not clear on what you are saying/asking, then. Are you saying you want to grab and post what's displayed when clicking that "Service Status" link?
Author of Multi-system Reactor and Reactor, DelayLight, Switchboard, and about a dozen other plugins that run on Vera and openLuup.
-
Not clear on what you are saying/asking, then. Are you saying you want to grab and post what's displayed when clicking that "Service Status" link?
@toggledbits yes exactly
-
That's an entirely different thing from parsing a JSON data response, which is what I was thinking you were doing based on the link to the previous thread (that's the subject matter of that thread). What you want to do is parse out portions of the contents of the returned HTML text. That's very doable with the tools available to you, but....
- It is generally regarded as sketchy, because there are no guarantees of their page structure — that' could change at the whim of their developer without notice and break your logic (as opposed to published data APIs which tend to be a bit more predictable and there's more incentive to keep them stable). So, IMO, it's a questionable thing to do.
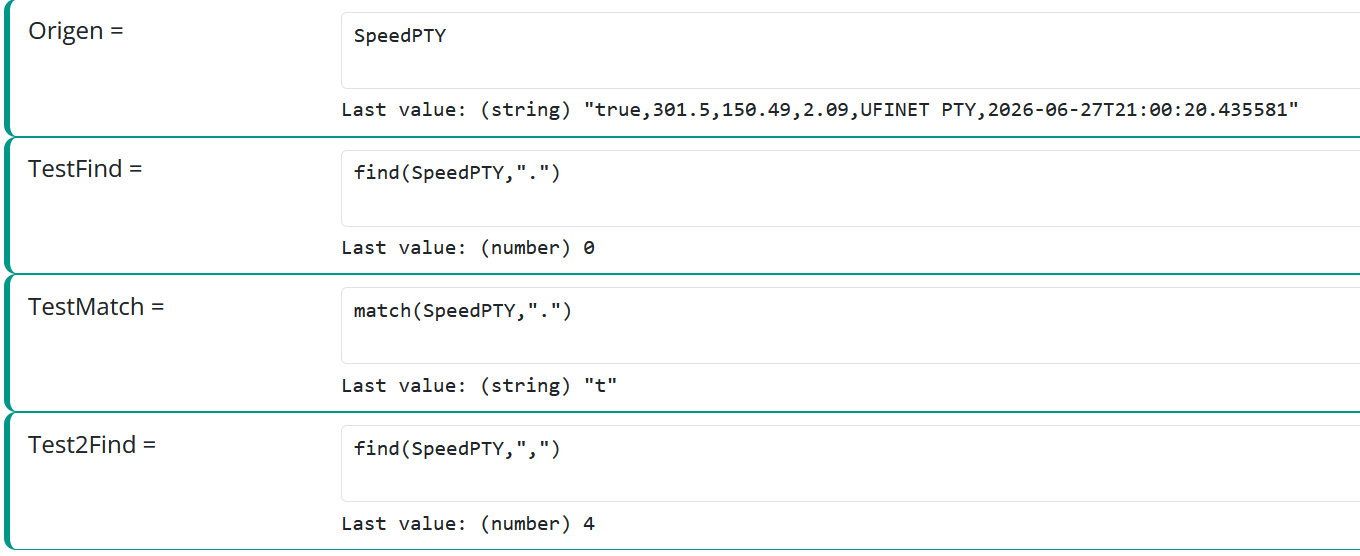
- If you're unfamiliar with regular expressions, it's going to be challenging in the extreme. You'll need to use Reactor expression functions like
match()andfind()and a handful of pretty complex regular expressions (specially formatted search patterns) to glean the target text from the HTML stream. The functions themselves are covered in the Reactor documentation, but that doesn't document regular expressions, which are a ubiquitous Linux/Unix feature (hence why these functions use them) and extensively documented elsewhere (see Google results). If you know regular expressions well, this would be challenging but very doable. But if you don't, you've got a big learning curve ahead of you, and as a first project, it's somewhat akin to building a bicycle for your first ride rather than buying one.