



[RESOLVED] PSA for Hubitat 2.3.7.x upgrade
-
If you are thinking about upgrading your Hubitat Elevation hub from 2.3.6 to 2.3.7, and you are using MSR.... wait! I was trying to resolve a different issue with the HE and didn't even think twice about how MSR would react. Well... MSR was not happy and was complaining that the events feed had become unresponsive. And my automations were not working either. I have since reverted back to 2.3.6 and will happily wait for @toggledbits to do his magic.

-
I did the update of my test C7 to 2.3.7.139 and so far so good. Note that this one does not have z-wave as the old bug that cloud backups can lock z-wave is back and I will wait for that to be fixed before upgrading my main box (I typically wait a month)
And what version of MSR are you running and how (barebone, PI, Windows, Docker, ...) Patrick will need more before magic will be done as you can read elsewhere on this forum. I am running the latest Docker image latest-23344-ca53d088. -
Same here. Docker image latest-23344-ca53d088. And I am aware that he would need more details. I'm not reporting this has a bug since he hasn't blessed 2.3.7 yet. I actually upgraded earlier in the day and some rules were triggering just fine. It wasn't until the evening when a lot of my logic was SUPER slow, delayed, or not working at all. Which would make sense if MSR couldn't chat with the hub.
I don't subscribe to the remote backups, so I don't think that bug will effect me. But good to know, thanks. -
I am also not seeing any issues. No quiet channel alerts or other problems with my system (now 2.3.7.139).
What causes the "reconnecting" alert?
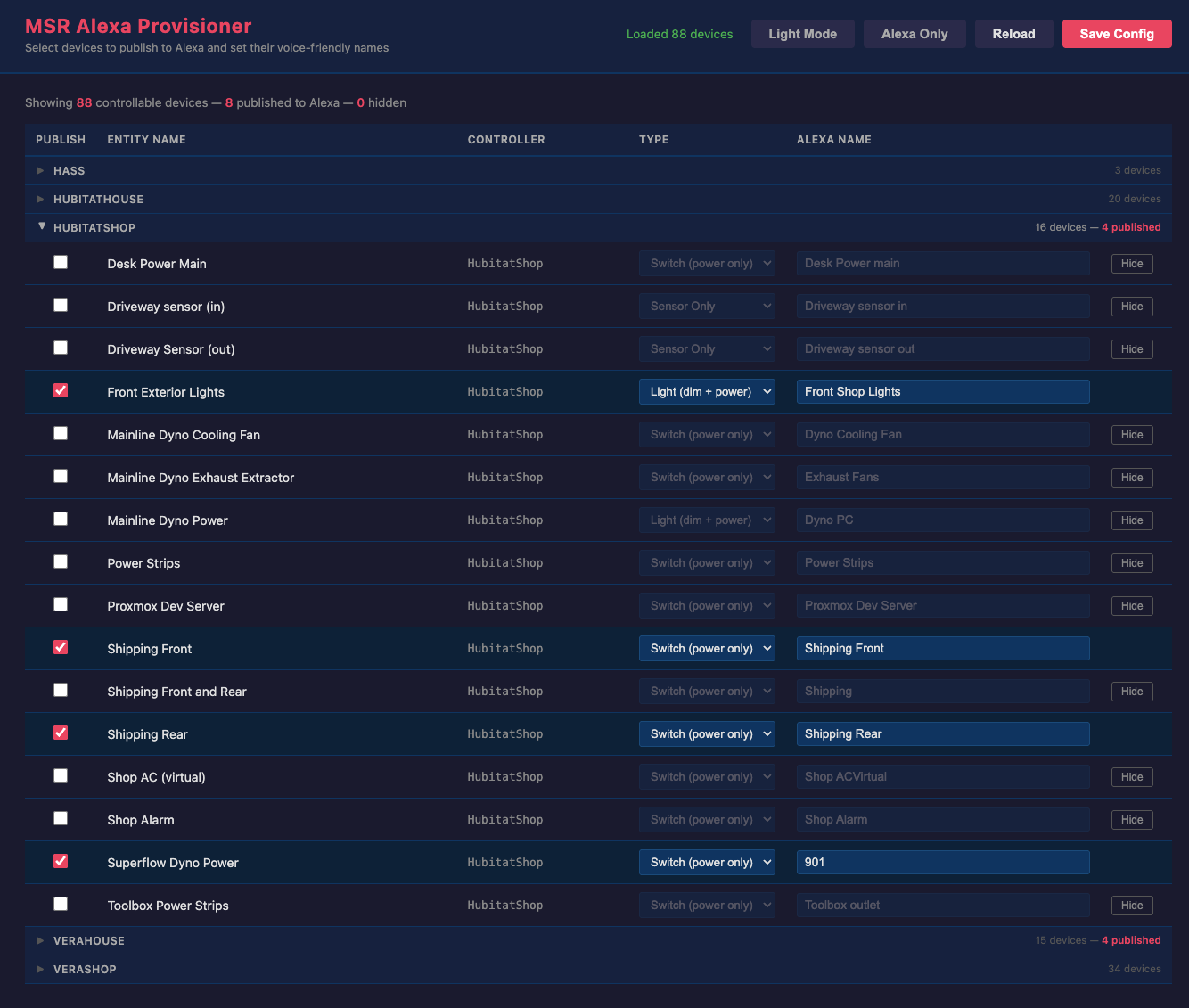
Some Hubitat systems don't say much. That is, when devices don't change, the websocket-based events feed goes quiet. It has been an unfortunate discovery in past Hubitat firmware that the websocket connection will remain connected but stop sending any data at all, so HubitatController attempts to detect this keeping a timer for received data on that connection. If nothing is received for two minutes (by default), HubitatController will send a refresh request to a selected non-battery device on the hub. Typically, this causes the hub to send something within 30 seconds; if not, the connection is assumed to have gone dead and is closed and recycled by HubitatController. This event causes the alert you were seeing. The probe is only used when no data has been received on the channel, so if you are looking at the logs, you may see probe messages spaced more than two minutes apart, or for very busy systems, you may not see any at all. The definition of busy depends on the devices themselves, not the number of devices. For example, if you have plugs that report voltage and current, these tend to be very chatty with their updates, and a single such device can take your system/mesh from quiet to busy because of it.
[...]2023-12-22T13:35:50.020Z <HubitatController#he_3:INFO> HubitatController#he_3 sending connection health probe to Switch#he_3>1 (events feed quiet) [...]2023-12-22T13:35:50.107Z <HubitatController#he_3:INFO> HubitatController#he_3 action x_hubitat_Refresh.refresh([Object]{ }) on Switch#he_3>1 succeededThe device probed is chosen at random. The device specifically has to support the Refresh capability on Hubitat (so HubitatController uses this as criterion for its selection). This generally works well a large percentage of the time, as evidenced by the few/no complaints received here since this mechanism was implemented. But it is possible that it can choose an inappropriate device nonetheless, such as something with a third-party driver that claims to implement Refresh but doesn't do anything useful with it. In that case, Reactor could occasionally report reconnects because the probe isn't stimulating any response on the events channel.
You can tell the randomly-selected device by looking for the following messages in your logs. At startup you will see:
[...]2023-12-21T18:27:29.202Z <HubitatController#he_3:NOTICE> HubitatController#he_3 A connection health probe device was not configured. A randomly-selected device will be used. [...]2023-12-21T18:27:29.202Z <HubitatController#he_3:NOTICE> Please refer to the HubitatController configuration docs for more information....and then sometime later, when the first probe occurs, you will see:
[...]2023-12-21T18:57:58.871Z <HubitatController#he_3:NOTICE> HubitatController#he_3 device "Zooz Double Plug-LEFT Outlet" (#"142") has been chosen for periodic health probes randomly (no specific device has been configured).You will not find this device-selection message until HubitatController determines that a probe is necessary. As I said above, that can be a long time or perhaps even never for busy systems, because the probe is only used if the events websocket is completely quiet for two minutes. Once a probe device is selected, that device is used until Reactor is restarted.
You can control the "probe device" used by telling Reactor which one to use in config. In that case, the burden is on you to choose an appropriate device, the driver for which must respond appropriately. You do this by adding a
probe_device: nnnline to your HubitatController'sconfigsection (inreactor.yaml), where nnn is the device number of the device to be used for probes. I recommend choosing a virtual switch or an AC-powered Z-Wave dimmer or switch.If the reconnect alerts don't go away after choosing a stable device, then you likely either have a hub problem or a network reliability problem.
Docs: https://reactor.toggledbits.com/docs/HubitatController/#other-configuration
-
Hmm.. OK. I was re-reading the HubitatController section of the docs and realized that I removed my Hub Information device a couple of months back. Perhaps that was part of the issue? I put it back and then upgraded to 2.3.7.140. So far so good. Hopefully it was the missing Hub Information device, or perhaps my HE was just having an off day? I'll monitor things and report back if there is any issues. Thanks all.
-
Just for the record, I have not been able to generate log evidence of the perception I have that there really is a failure in my rules, after the most recent updates (current version HE 2.3.7.141). I see that the delay has increased, or even rules have stopped responding, and I have to force the device to update the status. So, I disabled probe_device a long time ago, and I've enabled it again to see if it helps my perception. I'm still looking at the logs to see if I can detect anything. Thanks.
-

-
 T toggledbits locked this topic on
T toggledbits locked this topic on