



[Solved] Is there a cap or max number of devices a Global Reaction should not exceed?
-
Noticed in the last few nights that my Global Reaction to turn on a mere six lights in the evenings the same two devices no longer turn on. One is a dimming smart bulb, the other is a wall outlet.
This has been running flawlessly for months - just in the last few nights I've noticed these two devices being left behind and yes, it's always these two devices only.
"What changed?"
- No Hubitat firmware updates
- No new devices added to Hubitat
- list itemTwo MSR updates (the last two, I keep up with the latest)
- list itemHome Assistant releases (should have zero bearing, HA is nothing more than pretty dashboards)
- list itemAdded MQTT to MSR
I did do a z-wave "repair" last night and am waiting to see if this helps.
Is there any maximum or cap on number of devices that should be included in a Global Reaction?
*Marked as solved as the question asked was answered. The issue persists but the question was answered.
-
You don't say specifically, but when you say "dimming smart bulb", I'm thinking plugin, not ZWave. Can be more specific about the devices involved?
To answer the question asked, no, there's no limit.
-
It's a smartbulb, unfortunately Hubitat labels it as "Generic ZWave Smart Dimmer" which is misleading. This appears to be a GoControl Z-Wave Dimmable LED Light Bulb, LB60Z-1.
The second device is also misleadingly named in Hubitat as "Generic Z-Wave Relay". It is a GoControl WO15Z outlet.
-
Something I don't do on Hubitat that I have to do on Vera is pace actions... by default, VeraController will not send actions more frequently than every 25ms, and this pace seems to work (there have not been any complaints about missing actions that can't be attributed to other causes).
Maybe Hubitat needs it too... that would be a bummer. If adding delays to your reaction resolves the issue, that points in that direction.
-
OK, so I'll add some pacing to Hubitat as well. That's disappointing.
-
As this has worked flawlessly since MSR was released I'm inclined this is an unfortunate code change somewhere in one of the last releases of Hubitat - although, their last release was some weeks ago. Perhaps something in one of the last couple MSR releases "triggered" something they'd changed that had previously been dormant? Dunno. Thinking aloud.
-
None of the recent code changes to Hubitat would affect the performance of actions. The most notable of the changes was resolution of race condition during startup (when the Mode and HSM states are truly updated during startup), and not remotely close to the action implementation. All of the other changes are trivial, and again, not near the action implementation.
It would be easy to prove that the actions are being sent, if you want to run a more detailed test. The logging of actions on Hubitat is, and has been for some time, unconditional, so there will be (or not) evidence in the logs that the actions were sent to Hubitat. If you remove your recently-added delays and run like it was until it fails again, then peruse the logs, I'm pretty sure you'll find those actions were being attempted, at least. I strongly suspect they will be there. If not, there's a high chance we'll see another reason for why they are not.
This highlights, again, that reporting problems in the blind isn't useful. The logs are there for a reason. If something on the engine side isn't working as expected, it should be among the first places you look.
-
Of course. The performance of the Hubitat and the mesh are also an issue here. It's a complex system with many variables.
Author of Multi-system Reactor and Reactor, DelayLight, Switchboard, and about a dozen other plugins that run on Vera and openLuup.
-
Of course. The performance of the Hubitat and the mesh are also an issue here. It's a complex system with many variables.
I believe I am having a similar problem to the one discussed above, the perception that MSR is much faster than Hubitat.
I explain.
The MSR instantly receives everything that happens in Hubitat, any change of a device when it happens in Hubitat, immediately the MSR recognizes and if there is an action to be taken, immediately evaluates the action and fires the commands.
Then comes the problem, when the MSR triggers the actions for Hubitat devices, it loses actions, does not execute everything, hour an action is completed in all steps, hour fails. If I order to active 5 bulbs in sequence, almost always fails some, not always the same, varies on factors that I do not dominate.
And it doesn't need to have many actions, I have situations of quick reaction action as just turn on a light also failing.
Ok has the factor of the terrible signal from Hubitat (if compared to Vera), a bad management of the mesh network, where I see that the neighbours are poorly mapped and the mesh network poorly built.
But the failure scenario also happens with devices connected direct/next to the Hub.
In summary, the perception I have is that MSR is much faster than Hubitat that misses actions.
Include delay to each action would be a chaos, ok it can be a workaround, but it can't be the final solution.
Is it possible to have something in the configuration that creates the delay when sending each command to Hubitat? Like something like 0.5 seconds between actions?
I don't know if this would solve it, maybe you guys with more experience can point some way forward as the nightmare I had with Vera now happens on Hubitat.
Thanks.
-
I believe I am having a similar problem to the one discussed above, the perception that MSR is much faster than Hubitat.
I explain.
The MSR instantly receives everything that happens in Hubitat, any change of a device when it happens in Hubitat, immediately the MSR recognizes and if there is an action to be taken, immediately evaluates the action and fires the commands.
Then comes the problem, when the MSR triggers the actions for Hubitat devices, it loses actions, does not execute everything, hour an action is completed in all steps, hour fails. If I order to active 5 bulbs in sequence, almost always fails some, not always the same, varies on factors that I do not dominate.
And it doesn't need to have many actions, I have situations of quick reaction action as just turn on a light also failing.
Ok has the factor of the terrible signal from Hubitat (if compared to Vera), a bad management of the mesh network, where I see that the neighbours are poorly mapped and the mesh network poorly built.
But the failure scenario also happens with devices connected direct/next to the Hub.
In summary, the perception I have is that MSR is much faster than Hubitat that misses actions.
Include delay to each action would be a chaos, ok it can be a workaround, but it can't be the final solution.
Is it possible to have something in the configuration that creates the delay when sending each command to Hubitat? Like something like 0.5 seconds between actions?
I don't know if this would solve it, maybe you guys with more experience can point some way forward as the nightmare I had with Vera now happens on Hubitat.
Thanks.
@wmarcolin said in [Solved] Is there a cap or max number of devices a Global Reaction should not exceed?:
Is it possible to have something in the configuration that creates the delay when sending each command to Hubitat? Like something like 0.5 seconds between actions?
As stated in this thread, He added pacing to Hubitat.
From the docs:
action_pace — sets the minimum delay between actions sent to the hub (i.e. when a Reaction includes many); sending large numbers of requests can overwhelm the hub, it has been found, so this attempts to slow the pace to avoid this issue. The value must be an integer greater than 0, and the units are milliseconds; the default is 25."the nightmare I had with Vera now happens on Hubitat" If the problem was present before then I doubt that this will solve it.
Synology Docker MSR, Hubitat, Home Assistant, Homebridge, ZwaveJS, MQTT, NUT controller.
-
@wmarcolin said in [Solved] Is there a cap or max number of devices a Global Reaction should not exceed?:
Is it possible to have something in the configuration that creates the delay when sending each command to Hubitat? Like something like 0.5 seconds between actions?
As stated in this thread, He added pacing to Hubitat.
From the docs:
action_pace — sets the minimum delay between actions sent to the hub (i.e. when a Reaction includes many); sending large numbers of requests can overwhelm the hub, it has been found, so this attempts to slow the pace to avoid this issue. The value must be an integer greater than 0, and the units are milliseconds; the default is 25."the nightmare I had with Vera now happens on Hubitat" If the problem was present before then I doubt that this will solve it.
@sweetgenius per your history above, by adding this delay to all actions, did it solve the problem? What time frame are you using? Did you leave the default at 25 milliseconds, or did you add more?
-
@sweetgenius per your history above, by adding this delay to all actions, did it solve the problem? What time frame are you using? Did you leave the default at 25 milliseconds, or did you add more?
@wmarcolin said in [Solved] Is there a cap or max number of devices a Global Reaction should not exceed?:
per your history above,
I do not have any history above, Its not my thread nor did I comment until I read your post. I just read the thread and release notes and pointed out that both mention pacing.
Synology Docker MSR, Hubitat, Home Assistant, Homebridge, ZwaveJS, MQTT, NUT controller.
-
@wmarcolin said in [Solved] Is there a cap or max number of devices a Global Reaction should not exceed?:
per your history above,
I do not have any history above, Its not my thread nor did I comment until I read your post. I just read the thread and release notes and pointed out that both mention pacing.
@sweetgenius ops, thanks!
-
None of the recent code changes to Hubitat would affect the performance of actions. The most notable of the changes was resolution of race condition during startup (when the Mode and HSM states are truly updated during startup), and not remotely close to the action implementation. All of the other changes are trivial, and again, not near the action implementation.
It would be easy to prove that the actions are being sent, if you want to run a more detailed test. The logging of actions on Hubitat is, and has been for some time, unconditional, so there will be (or not) evidence in the logs that the actions were sent to Hubitat. If you remove your recently-added delays and run like it was until it fails again, then peruse the logs, I'm pretty sure you'll find those actions were being attempted, at least. I strongly suspect they will be there. If not, there's a high chance we'll see another reason for why they are not.
This highlights, again, that reporting problems in the blind isn't useful. The logs are there for a reason. If something on the engine side isn't working as expected, it should be among the first places you look.
@toggledbits hi master!
I am going into a state of despair with Hubitat, and thinking that I have made a bad switch from VeraPlus to Hubitat.
Well, as you always comment, look at the log, as I already commented my suspicion that the MSR sent all commands to Hubitat, and this one that failed was confirmed, as you mention in your message.
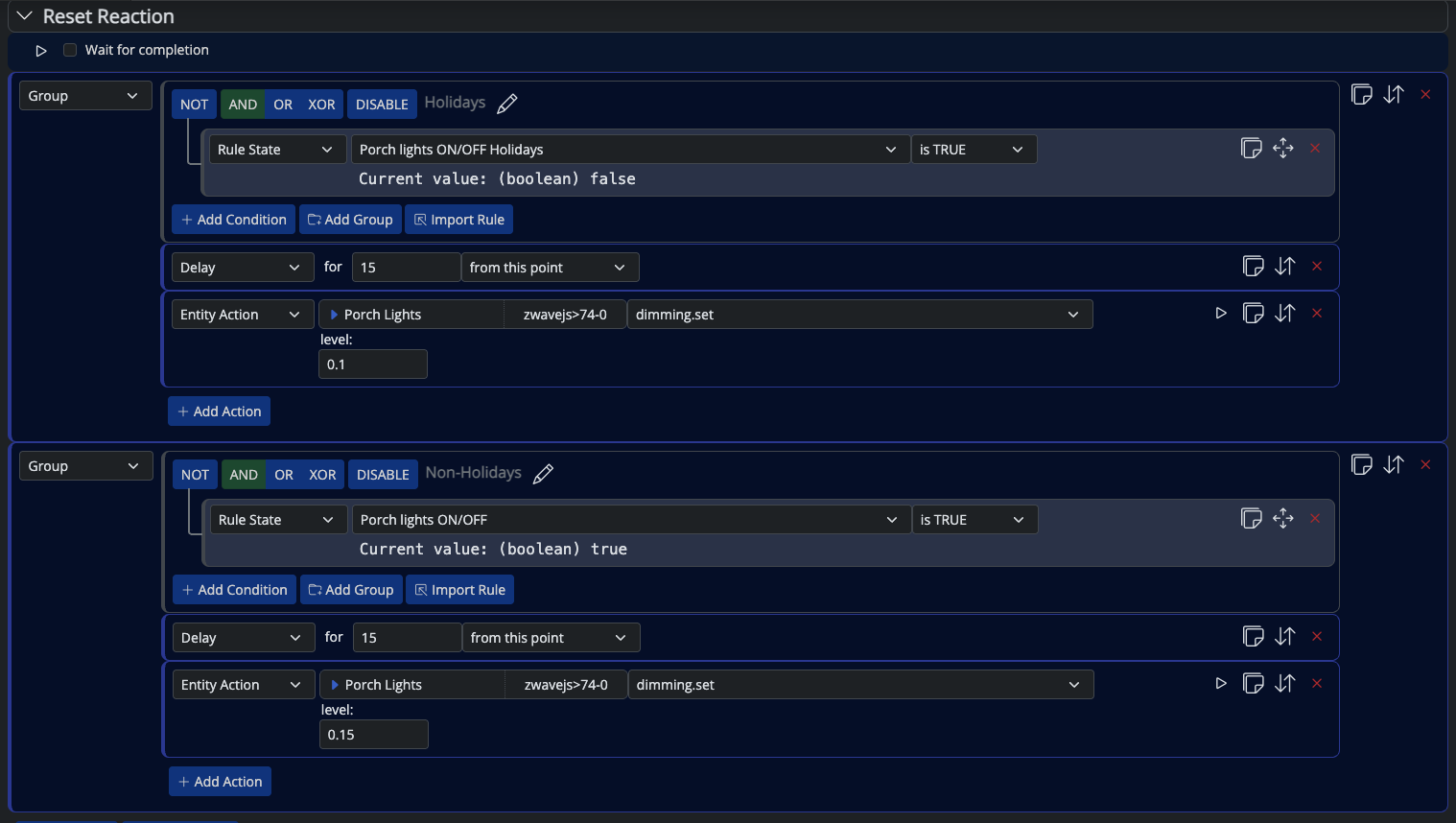
Routines below.
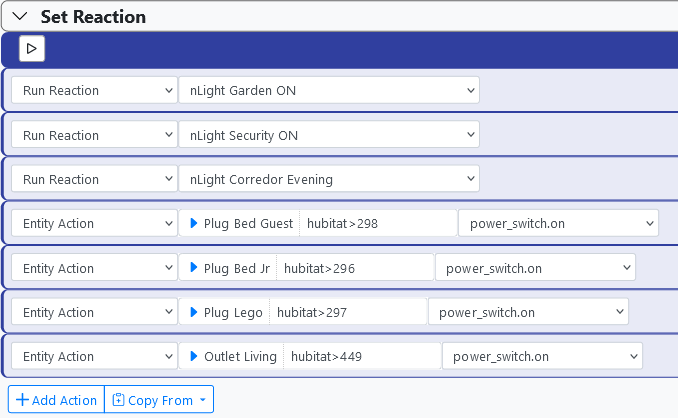
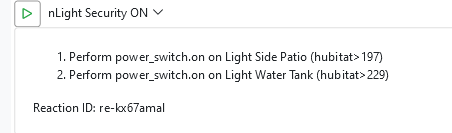
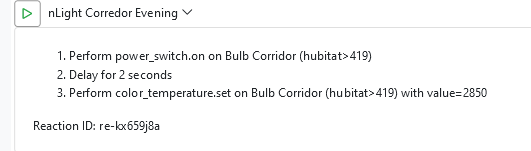
Looking at the log, I don't understand what sequence the MSR performed, but I see that all of the above actions were sent to Hubitat without fail.
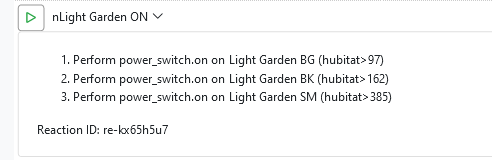
[latest-21349]2021-12-17T01:46:57.319Z <Rule:NOTICE> Rule#rule-kx9oxcss configuration changed; reloading [latest-21349]2021-12-17T01:46:57.321Z <Rule:NOTICE> Rule#rule-kx9oxcss stopping rule [latest-21349]2021-12-17T01:46:57.324Z <Rule:NOTICE> Rule Rule#rule-kx9oxcss stopped [latest-21349]2021-12-17T01:46:57.325Z <Rule:INFO> Rule#rule-kx9oxcss (nGarden) started [latest-21349]2021-12-17T01:46:57.327Z <Rule:INFO> nGarden (Rule#rule-kx9oxcss) SET! [latest-21349]2021-12-17T01:46:57.331Z <Engine:INFO> Enqueueing "nGarden<SET>" (rule-kx9oxcss:S) [latest-21349]2021-12-17T01:46:57.345Z <Engine:NOTICE> Starting reaction nGarden<SET> (rule-kx9oxcss:S) [latest-21349]2021-12-17T01:46:57.346Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>298: http://192.168.33.22/apps/api/67/devices/298/on [latest-21349]2021-12-17T01:46:57.348Z <Engine:INFO> Enqueueing "nLight Garden ON" (re-kx65h5u7) [latest-21349]2021-12-17T01:46:57.350Z <Engine:INFO> Enqueueing "nLight Security ON" (re-kx67amal) [latest-21349]2021-12-17T01:46:57.352Z <Engine:INFO> Enqueueing "nLight Corredor Evening" (re-kx659j8a) [latest-21349]2021-12-17T01:46:57.377Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 4 [latest-21349]2021-12-17T01:46:57.378Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>296: http://192.168.33.22/apps/api/67/devices/296/on [latest-21349]2021-12-17T01:46:57.379Z <Engine:NOTICE> Starting reaction nLight Garden ON (re-kx65h5u7) [latest-21349]2021-12-17T01:46:57.380Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>97: http://192.168.33.22/apps/api/67/devices/97/on [latest-21349]2021-12-17T01:46:57.381Z <Engine:NOTICE> Starting reaction nLight Security ON (re-kx67amal) [latest-21349]2021-12-17T01:46:57.382Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>197: http://192.168.33.22/apps/api/67/devices/197/on [latest-21349]2021-12-17T01:46:57.383Z <Engine:NOTICE> Starting reaction nLight Corredor Evening (re-kx659j8a) [latest-21349]2021-12-17T01:46:57.384Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>419: http://192.168.33.22/apps/api/67/devices/419/on [latest-21349]2021-12-17T01:46:57.456Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 5 [latest-21349]2021-12-17T01:46:57.457Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>297: http://192.168.33.22/apps/api/67/devices/297/on [latest-21349]2021-12-17T01:46:57.563Z <Engine:NOTICE> Resuming reaction nLight Garden ON (re-kx65h5u7) from step 1 [latest-21349]2021-12-17T01:46:57.564Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>162: http://192.168.33.22/apps/api/67/devices/162/on [latest-21349]2021-12-17T01:46:57.673Z <Engine:NOTICE> Resuming reaction nLight Security ON (re-kx67amal) from step 1 [latest-21349]2021-12-17T01:46:57.674Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>229: http://192.168.33.22/apps/api/67/devices/229/on [latest-21349]2021-12-17T01:46:57.782Z <Engine:NOTICE> Resuming reaction nLight Corredor Evening (re-kx659j8a) from step 1 [latest-21349]2021-12-17T01:46:57.784Z <Engine:NOTICE> nLight Corredor Evening delaying until 1639705619783<16/12/2021 20:46:59> [latest-21349]2021-12-17T01:46:57.889Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 6 [latest-21349]2021-12-17T01:46:57.890Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>449: http://192.168.33.22/apps/api/67/devices/449/on [latest-21349]2021-12-17T01:46:57.995Z <Engine:NOTICE> Resuming reaction nLight Garden ON (re-kx65h5u7) from step 2 [latest-21349]2021-12-17T01:46:57.996Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>385: http://192.168.33.22/apps/api/67/devices/385/on [latest-21349]2021-12-17T01:46:58.106Z <Engine:NOTICE> Resuming reaction nLight Security ON (re-kx67amal) from step 2 [latest-21349]2021-12-17T01:46:58.106Z <Engine:INFO> nLight Security ON all actions completed. [latest-21349]2021-12-17T01:46:58.214Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 7 [latest-21349]2021-12-17T01:46:58.215Z <Engine:INFO> nGarden<SET> all actions completed. [latest-21349]2021-12-17T01:46:58.321Z <Engine:NOTICE> Resuming reaction nLight Garden ON (re-kx65h5u7) from step 3 [latest-21349]2021-12-17T01:46:58.322Z <Engine:INFO> nLight Garden ON all actions completed. [latest-21349]2021-12-17T01:46:59.795Z <Engine:NOTICE> Resuming reaction nLight Corredor Evening (re-kx659j8a) from step 2 [latest-21349]2021-12-17T01:46:59.796Z <HubitatController:null> HubitatController#hubitat final action path for color_temperature.set on Entity#hubitat>419: http://192.168.33.22/apps/api/67/devices/419/setColorTemperature/2850 [latest-21349]2021-12-17T01:46:59.800Z <Engine:NOTICE> Resuming reaction nLight Corredor Evening (re-kx659j8a) from step 3 [latest-21349]2021-12-17T01:46:59.800Z <Engine:INFO> nLight Corredor Evening all actions completed.I have checked each of the devices, all are in the log. I am even using the action_pace: 100 setting and I see that the interval was obeyed.
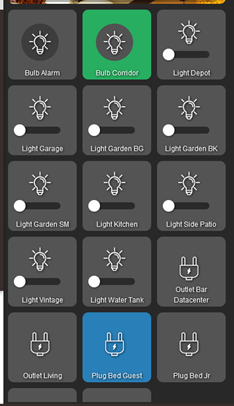
But out of 10 lights that should be on, as you can see on the Hubitat's panel only 2 were.
Sorry @toggledbits to ask, and I will understand if you don't answer because I see that the MSR is perfect.
Any recommendations for Hubitat? Reset the whole Z-wave radio and pair it again? Any APP that can check radio occupancy or Hubitat processing? Maybe you with your experience can give me some guidance, and again sorry, I know it is not MSR, but I'm almost back to the Vera with all its problems of drive and evolution.
-
@toggledbits hi master!
I am going into a state of despair with Hubitat, and thinking that I have made a bad switch from VeraPlus to Hubitat.
Well, as you always comment, look at the log, as I already commented my suspicion that the MSR sent all commands to Hubitat, and this one that failed was confirmed, as you mention in your message.
Routines below.
Looking at the log, I don't understand what sequence the MSR performed, but I see that all of the above actions were sent to Hubitat without fail.
[latest-21349]2021-12-17T01:46:57.319Z <Rule:NOTICE> Rule#rule-kx9oxcss configuration changed; reloading [latest-21349]2021-12-17T01:46:57.321Z <Rule:NOTICE> Rule#rule-kx9oxcss stopping rule [latest-21349]2021-12-17T01:46:57.324Z <Rule:NOTICE> Rule Rule#rule-kx9oxcss stopped [latest-21349]2021-12-17T01:46:57.325Z <Rule:INFO> Rule#rule-kx9oxcss (nGarden) started [latest-21349]2021-12-17T01:46:57.327Z <Rule:INFO> nGarden (Rule#rule-kx9oxcss) SET! [latest-21349]2021-12-17T01:46:57.331Z <Engine:INFO> Enqueueing "nGarden<SET>" (rule-kx9oxcss:S) [latest-21349]2021-12-17T01:46:57.345Z <Engine:NOTICE> Starting reaction nGarden<SET> (rule-kx9oxcss:S) [latest-21349]2021-12-17T01:46:57.346Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>298: http://192.168.33.22/apps/api/67/devices/298/on [latest-21349]2021-12-17T01:46:57.348Z <Engine:INFO> Enqueueing "nLight Garden ON" (re-kx65h5u7) [latest-21349]2021-12-17T01:46:57.350Z <Engine:INFO> Enqueueing "nLight Security ON" (re-kx67amal) [latest-21349]2021-12-17T01:46:57.352Z <Engine:INFO> Enqueueing "nLight Corredor Evening" (re-kx659j8a) [latest-21349]2021-12-17T01:46:57.377Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 4 [latest-21349]2021-12-17T01:46:57.378Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>296: http://192.168.33.22/apps/api/67/devices/296/on [latest-21349]2021-12-17T01:46:57.379Z <Engine:NOTICE> Starting reaction nLight Garden ON (re-kx65h5u7) [latest-21349]2021-12-17T01:46:57.380Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>97: http://192.168.33.22/apps/api/67/devices/97/on [latest-21349]2021-12-17T01:46:57.381Z <Engine:NOTICE> Starting reaction nLight Security ON (re-kx67amal) [latest-21349]2021-12-17T01:46:57.382Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>197: http://192.168.33.22/apps/api/67/devices/197/on [latest-21349]2021-12-17T01:46:57.383Z <Engine:NOTICE> Starting reaction nLight Corredor Evening (re-kx659j8a) [latest-21349]2021-12-17T01:46:57.384Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>419: http://192.168.33.22/apps/api/67/devices/419/on [latest-21349]2021-12-17T01:46:57.456Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 5 [latest-21349]2021-12-17T01:46:57.457Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>297: http://192.168.33.22/apps/api/67/devices/297/on [latest-21349]2021-12-17T01:46:57.563Z <Engine:NOTICE> Resuming reaction nLight Garden ON (re-kx65h5u7) from step 1 [latest-21349]2021-12-17T01:46:57.564Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>162: http://192.168.33.22/apps/api/67/devices/162/on [latest-21349]2021-12-17T01:46:57.673Z <Engine:NOTICE> Resuming reaction nLight Security ON (re-kx67amal) from step 1 [latest-21349]2021-12-17T01:46:57.674Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>229: http://192.168.33.22/apps/api/67/devices/229/on [latest-21349]2021-12-17T01:46:57.782Z <Engine:NOTICE> Resuming reaction nLight Corredor Evening (re-kx659j8a) from step 1 [latest-21349]2021-12-17T01:46:57.784Z <Engine:NOTICE> nLight Corredor Evening delaying until 1639705619783<16/12/2021 20:46:59> [latest-21349]2021-12-17T01:46:57.889Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 6 [latest-21349]2021-12-17T01:46:57.890Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>449: http://192.168.33.22/apps/api/67/devices/449/on [latest-21349]2021-12-17T01:46:57.995Z <Engine:NOTICE> Resuming reaction nLight Garden ON (re-kx65h5u7) from step 2 [latest-21349]2021-12-17T01:46:57.996Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>385: http://192.168.33.22/apps/api/67/devices/385/on [latest-21349]2021-12-17T01:46:58.106Z <Engine:NOTICE> Resuming reaction nLight Security ON (re-kx67amal) from step 2 [latest-21349]2021-12-17T01:46:58.106Z <Engine:INFO> nLight Security ON all actions completed. [latest-21349]2021-12-17T01:46:58.214Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 7 [latest-21349]2021-12-17T01:46:58.215Z <Engine:INFO> nGarden<SET> all actions completed. [latest-21349]2021-12-17T01:46:58.321Z <Engine:NOTICE> Resuming reaction nLight Garden ON (re-kx65h5u7) from step 3 [latest-21349]2021-12-17T01:46:58.322Z <Engine:INFO> nLight Garden ON all actions completed. [latest-21349]2021-12-17T01:46:59.795Z <Engine:NOTICE> Resuming reaction nLight Corredor Evening (re-kx659j8a) from step 2 [latest-21349]2021-12-17T01:46:59.796Z <HubitatController:null> HubitatController#hubitat final action path for color_temperature.set on Entity#hubitat>419: http://192.168.33.22/apps/api/67/devices/419/setColorTemperature/2850 [latest-21349]2021-12-17T01:46:59.800Z <Engine:NOTICE> Resuming reaction nLight Corredor Evening (re-kx659j8a) from step 3 [latest-21349]2021-12-17T01:46:59.800Z <Engine:INFO> nLight Corredor Evening all actions completed.I have checked each of the devices, all are in the log. I am even using the action_pace: 100 setting and I see that the interval was obeyed.
But out of 10 lights that should be on, as you can see on the Hubitat's panel only 2 were.
Sorry @toggledbits to ask, and I will understand if you don't answer because I see that the MSR is perfect.
Any recommendations for Hubitat? Reset the whole Z-wave radio and pair it again? Any APP that can check radio occupancy or Hubitat processing? Maybe you with your experience can give me some guidance, and again sorry, I know it is not MSR, but I'm almost back to the Vera with all its problems of drive and evolution.
@wmarcolin I don't have a Hubitat myself but have you looked at the logs on the hub per https://docs.hubitat.com/index.php?title=Logs for hints of what is happening when set reaction fires?
-
@toggledbits hi master!
I am going into a state of despair with Hubitat, and thinking that I have made a bad switch from VeraPlus to Hubitat.
Well, as you always comment, look at the log, as I already commented my suspicion that the MSR sent all commands to Hubitat, and this one that failed was confirmed, as you mention in your message.
Routines below.
Looking at the log, I don't understand what sequence the MSR performed, but I see that all of the above actions were sent to Hubitat without fail.
[latest-21349]2021-12-17T01:46:57.319Z <Rule:NOTICE> Rule#rule-kx9oxcss configuration changed; reloading [latest-21349]2021-12-17T01:46:57.321Z <Rule:NOTICE> Rule#rule-kx9oxcss stopping rule [latest-21349]2021-12-17T01:46:57.324Z <Rule:NOTICE> Rule Rule#rule-kx9oxcss stopped [latest-21349]2021-12-17T01:46:57.325Z <Rule:INFO> Rule#rule-kx9oxcss (nGarden) started [latest-21349]2021-12-17T01:46:57.327Z <Rule:INFO> nGarden (Rule#rule-kx9oxcss) SET! [latest-21349]2021-12-17T01:46:57.331Z <Engine:INFO> Enqueueing "nGarden<SET>" (rule-kx9oxcss:S) [latest-21349]2021-12-17T01:46:57.345Z <Engine:NOTICE> Starting reaction nGarden<SET> (rule-kx9oxcss:S) [latest-21349]2021-12-17T01:46:57.346Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>298: http://192.168.33.22/apps/api/67/devices/298/on [latest-21349]2021-12-17T01:46:57.348Z <Engine:INFO> Enqueueing "nLight Garden ON" (re-kx65h5u7) [latest-21349]2021-12-17T01:46:57.350Z <Engine:INFO> Enqueueing "nLight Security ON" (re-kx67amal) [latest-21349]2021-12-17T01:46:57.352Z <Engine:INFO> Enqueueing "nLight Corredor Evening" (re-kx659j8a) [latest-21349]2021-12-17T01:46:57.377Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 4 [latest-21349]2021-12-17T01:46:57.378Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>296: http://192.168.33.22/apps/api/67/devices/296/on [latest-21349]2021-12-17T01:46:57.379Z <Engine:NOTICE> Starting reaction nLight Garden ON (re-kx65h5u7) [latest-21349]2021-12-17T01:46:57.380Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>97: http://192.168.33.22/apps/api/67/devices/97/on [latest-21349]2021-12-17T01:46:57.381Z <Engine:NOTICE> Starting reaction nLight Security ON (re-kx67amal) [latest-21349]2021-12-17T01:46:57.382Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>197: http://192.168.33.22/apps/api/67/devices/197/on [latest-21349]2021-12-17T01:46:57.383Z <Engine:NOTICE> Starting reaction nLight Corredor Evening (re-kx659j8a) [latest-21349]2021-12-17T01:46:57.384Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>419: http://192.168.33.22/apps/api/67/devices/419/on [latest-21349]2021-12-17T01:46:57.456Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 5 [latest-21349]2021-12-17T01:46:57.457Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>297: http://192.168.33.22/apps/api/67/devices/297/on [latest-21349]2021-12-17T01:46:57.563Z <Engine:NOTICE> Resuming reaction nLight Garden ON (re-kx65h5u7) from step 1 [latest-21349]2021-12-17T01:46:57.564Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>162: http://192.168.33.22/apps/api/67/devices/162/on [latest-21349]2021-12-17T01:46:57.673Z <Engine:NOTICE> Resuming reaction nLight Security ON (re-kx67amal) from step 1 [latest-21349]2021-12-17T01:46:57.674Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>229: http://192.168.33.22/apps/api/67/devices/229/on [latest-21349]2021-12-17T01:46:57.782Z <Engine:NOTICE> Resuming reaction nLight Corredor Evening (re-kx659j8a) from step 1 [latest-21349]2021-12-17T01:46:57.784Z <Engine:NOTICE> nLight Corredor Evening delaying until 1639705619783<16/12/2021 20:46:59> [latest-21349]2021-12-17T01:46:57.889Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 6 [latest-21349]2021-12-17T01:46:57.890Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>449: http://192.168.33.22/apps/api/67/devices/449/on [latest-21349]2021-12-17T01:46:57.995Z <Engine:NOTICE> Resuming reaction nLight Garden ON (re-kx65h5u7) from step 2 [latest-21349]2021-12-17T01:46:57.996Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>385: http://192.168.33.22/apps/api/67/devices/385/on [latest-21349]2021-12-17T01:46:58.106Z <Engine:NOTICE> Resuming reaction nLight Security ON (re-kx67amal) from step 2 [latest-21349]2021-12-17T01:46:58.106Z <Engine:INFO> nLight Security ON all actions completed. [latest-21349]2021-12-17T01:46:58.214Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 7 [latest-21349]2021-12-17T01:46:58.215Z <Engine:INFO> nGarden<SET> all actions completed. [latest-21349]2021-12-17T01:46:58.321Z <Engine:NOTICE> Resuming reaction nLight Garden ON (re-kx65h5u7) from step 3 [latest-21349]2021-12-17T01:46:58.322Z <Engine:INFO> nLight Garden ON all actions completed. [latest-21349]2021-12-17T01:46:59.795Z <Engine:NOTICE> Resuming reaction nLight Corredor Evening (re-kx659j8a) from step 2 [latest-21349]2021-12-17T01:46:59.796Z <HubitatController:null> HubitatController#hubitat final action path for color_temperature.set on Entity#hubitat>419: http://192.168.33.22/apps/api/67/devices/419/setColorTemperature/2850 [latest-21349]2021-12-17T01:46:59.800Z <Engine:NOTICE> Resuming reaction nLight Corredor Evening (re-kx659j8a) from step 3 [latest-21349]2021-12-17T01:46:59.800Z <Engine:INFO> nLight Corredor Evening all actions completed.I have checked each of the devices, all are in the log. I am even using the action_pace: 100 setting and I see that the interval was obeyed.
But out of 10 lights that should be on, as you can see on the Hubitat's panel only 2 were.
Sorry @toggledbits to ask, and I will understand if you don't answer because I see that the MSR is perfect.
Any recommendations for Hubitat? Reset the whole Z-wave radio and pair it again? Any APP that can check radio occupancy or Hubitat processing? Maybe you with your experience can give me some guidance, and again sorry, I know it is not MSR, but I'm almost back to the Vera with all its problems of drive and evolution.
@wmarcolin Something you've not surfaced, wireless interference. How close is your Hubitat to your WiFi router (they should not be near each other as they will interfere due to the frequencies in use), how close are your z-wave hubs to each other, etc.
Are all devices the kind that are plugged into electricity? I've discovered with some battery-operated devices that they sleep a lot to conserve battery and that delays actions. My iblind controllers are a perfect example: sending a refresh first and then the command seems to make them much happier regarding responding to commands.
As @toggledbits noted in a response to me previously in the thread (and you've supported), the mesh plays a huge role, too.
I had a Veralite and then moved to a VeraSecure. I've done direct comparisons between my VeraSecure and Hubitat using MSR to trigger the rules and the Hubitat was much faster. That, amongst other reasons, is why my VeraSecure is now completely offline.
-
@toggledbits hi master!
I am going into a state of despair with Hubitat, and thinking that I have made a bad switch from VeraPlus to Hubitat.
Well, as you always comment, look at the log, as I already commented my suspicion that the MSR sent all commands to Hubitat, and this one that failed was confirmed, as you mention in your message.
Routines below.
Looking at the log, I don't understand what sequence the MSR performed, but I see that all of the above actions were sent to Hubitat without fail.
[latest-21349]2021-12-17T01:46:57.319Z <Rule:NOTICE> Rule#rule-kx9oxcss configuration changed; reloading [latest-21349]2021-12-17T01:46:57.321Z <Rule:NOTICE> Rule#rule-kx9oxcss stopping rule [latest-21349]2021-12-17T01:46:57.324Z <Rule:NOTICE> Rule Rule#rule-kx9oxcss stopped [latest-21349]2021-12-17T01:46:57.325Z <Rule:INFO> Rule#rule-kx9oxcss (nGarden) started [latest-21349]2021-12-17T01:46:57.327Z <Rule:INFO> nGarden (Rule#rule-kx9oxcss) SET! [latest-21349]2021-12-17T01:46:57.331Z <Engine:INFO> Enqueueing "nGarden<SET>" (rule-kx9oxcss:S) [latest-21349]2021-12-17T01:46:57.345Z <Engine:NOTICE> Starting reaction nGarden<SET> (rule-kx9oxcss:S) [latest-21349]2021-12-17T01:46:57.346Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>298: http://192.168.33.22/apps/api/67/devices/298/on [latest-21349]2021-12-17T01:46:57.348Z <Engine:INFO> Enqueueing "nLight Garden ON" (re-kx65h5u7) [latest-21349]2021-12-17T01:46:57.350Z <Engine:INFO> Enqueueing "nLight Security ON" (re-kx67amal) [latest-21349]2021-12-17T01:46:57.352Z <Engine:INFO> Enqueueing "nLight Corredor Evening" (re-kx659j8a) [latest-21349]2021-12-17T01:46:57.377Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 4 [latest-21349]2021-12-17T01:46:57.378Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>296: http://192.168.33.22/apps/api/67/devices/296/on [latest-21349]2021-12-17T01:46:57.379Z <Engine:NOTICE> Starting reaction nLight Garden ON (re-kx65h5u7) [latest-21349]2021-12-17T01:46:57.380Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>97: http://192.168.33.22/apps/api/67/devices/97/on [latest-21349]2021-12-17T01:46:57.381Z <Engine:NOTICE> Starting reaction nLight Security ON (re-kx67amal) [latest-21349]2021-12-17T01:46:57.382Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>197: http://192.168.33.22/apps/api/67/devices/197/on [latest-21349]2021-12-17T01:46:57.383Z <Engine:NOTICE> Starting reaction nLight Corredor Evening (re-kx659j8a) [latest-21349]2021-12-17T01:46:57.384Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>419: http://192.168.33.22/apps/api/67/devices/419/on [latest-21349]2021-12-17T01:46:57.456Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 5 [latest-21349]2021-12-17T01:46:57.457Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>297: http://192.168.33.22/apps/api/67/devices/297/on [latest-21349]2021-12-17T01:46:57.563Z <Engine:NOTICE> Resuming reaction nLight Garden ON (re-kx65h5u7) from step 1 [latest-21349]2021-12-17T01:46:57.564Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>162: http://192.168.33.22/apps/api/67/devices/162/on [latest-21349]2021-12-17T01:46:57.673Z <Engine:NOTICE> Resuming reaction nLight Security ON (re-kx67amal) from step 1 [latest-21349]2021-12-17T01:46:57.674Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>229: http://192.168.33.22/apps/api/67/devices/229/on [latest-21349]2021-12-17T01:46:57.782Z <Engine:NOTICE> Resuming reaction nLight Corredor Evening (re-kx659j8a) from step 1 [latest-21349]2021-12-17T01:46:57.784Z <Engine:NOTICE> nLight Corredor Evening delaying until 1639705619783<16/12/2021 20:46:59> [latest-21349]2021-12-17T01:46:57.889Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 6 [latest-21349]2021-12-17T01:46:57.890Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>449: http://192.168.33.22/apps/api/67/devices/449/on [latest-21349]2021-12-17T01:46:57.995Z <Engine:NOTICE> Resuming reaction nLight Garden ON (re-kx65h5u7) from step 2 [latest-21349]2021-12-17T01:46:57.996Z <HubitatController:null> HubitatController#hubitat final action path for power_switch.on on Entity#hubitat>385: http://192.168.33.22/apps/api/67/devices/385/on [latest-21349]2021-12-17T01:46:58.106Z <Engine:NOTICE> Resuming reaction nLight Security ON (re-kx67amal) from step 2 [latest-21349]2021-12-17T01:46:58.106Z <Engine:INFO> nLight Security ON all actions completed. [latest-21349]2021-12-17T01:46:58.214Z <Engine:NOTICE> Resuming reaction nGarden<SET> (rule-kx9oxcss:S) from step 7 [latest-21349]2021-12-17T01:46:58.215Z <Engine:INFO> nGarden<SET> all actions completed. [latest-21349]2021-12-17T01:46:58.321Z <Engine:NOTICE> Resuming reaction nLight Garden ON (re-kx65h5u7) from step 3 [latest-21349]2021-12-17T01:46:58.322Z <Engine:INFO> nLight Garden ON all actions completed. [latest-21349]2021-12-17T01:46:59.795Z <Engine:NOTICE> Resuming reaction nLight Corredor Evening (re-kx659j8a) from step 2 [latest-21349]2021-12-17T01:46:59.796Z <HubitatController:null> HubitatController#hubitat final action path for color_temperature.set on Entity#hubitat>419: http://192.168.33.22/apps/api/67/devices/419/setColorTemperature/2850 [latest-21349]2021-12-17T01:46:59.800Z <Engine:NOTICE> Resuming reaction nLight Corredor Evening (re-kx659j8a) from step 3 [latest-21349]2021-12-17T01:46:59.800Z <Engine:INFO> nLight Corredor Evening all actions completed.I have checked each of the devices, all are in the log. I am even using the action_pace: 100 setting and I see that the interval was obeyed.
But out of 10 lights that should be on, as you can see on the Hubitat's panel only 2 were.
Sorry @toggledbits to ask, and I will understand if you don't answer because I see that the MSR is perfect.
Any recommendations for Hubitat? Reset the whole Z-wave radio and pair it again? Any APP that can check radio occupancy or Hubitat processing? Maybe you with your experience can give me some guidance, and again sorry, I know it is not MSR, but I'm almost back to the Vera with all its problems of drive and evolution.
@wmarcolin said in [Solved] Is there a cap or max number of devices a Global Reaction should not exceed?:
Looking at the log, I don't understand what sequence the MSR performed, but I see that all of the above actions were sent to Hubitat
Hmmm. I can't answer for the Hubitat part, but I explain the order. The first three actions in nGarden<SET> are Run Reaction, so these enqueue those reactions with the executive -- they are not run in-line. That's why you see the three "Enqueueing" lines, followed by a resume of nGarden<Set> from step 4. We see the action output for device 298, which is step 3 (numbered from 0), before the enqueue messages because enqueueing itself is an asynchronous operation, so the executive quickly started the three Run Reaction enqueue requests, then ran the device 298 Entity Action. Running an entity action is asynchronous, so the executive had to wait for that operation to finish. Since it went into a wait state, the tasks for the three Run Reaction enqueues could run, so they did. When they were done and the 298 device action was finished sending, nGarden<SET> could then resume from step 4 (numbered from 0, so 5 as we look at it). That's device 296 so we see that on the next line. Again, device actions have to wait for the send, so execution paused of nGarden<Set> paused there, which allowed nLight Garden ON, the first of the three enqueued reactions, to start and send its first command to device 97. That blocked that reaction, so nLight Security ON was next in the queue and it started and sent its first device action to 197. That blocked that reaction, so nLight Corredor Evening started and ran its first action against 419. It blocked, of course, so everything paused about 70ms until nGarden<Set> became the first ready task, so it resumed at step 5 (from 0, or 6 as we count from 1). And so on, until all were sent.
I'm not sure what your pacing configuration was at this point, but overall it appears about right for the number of tasks sent. It's hard to tell without more debug on, and maybe I'll add some "standard" messages about device queueing while we're looking at this (since debug on a Controller instance can be very large and a bit like sipping from a firehouse).
One thing to note also is that each Entity Action blocks while sending -- the reaction waits for the hub to acknowledge the request. For that to happen, the request must be sent, and the hub has to give an HTTP 200 (OK) response to the request (if it gives an error, that would be logged, and there are no errors logged in this snippet). So at the least, the hub has acknowledged the request, but that doesn't mean it has completed the request, let alone that the request was successful in its overall execution (e.g. manipulating the device). That's a different and much bigger problem.
I'm not done looking at this. I want to study the timing more carefully as well. There's something about it that doesn't seem right to me. As I said, I'm going to add some more standard (non-debug) diagnostic output to this while we're looking at it, and roll a new release later today, for you to try and send me new logs.