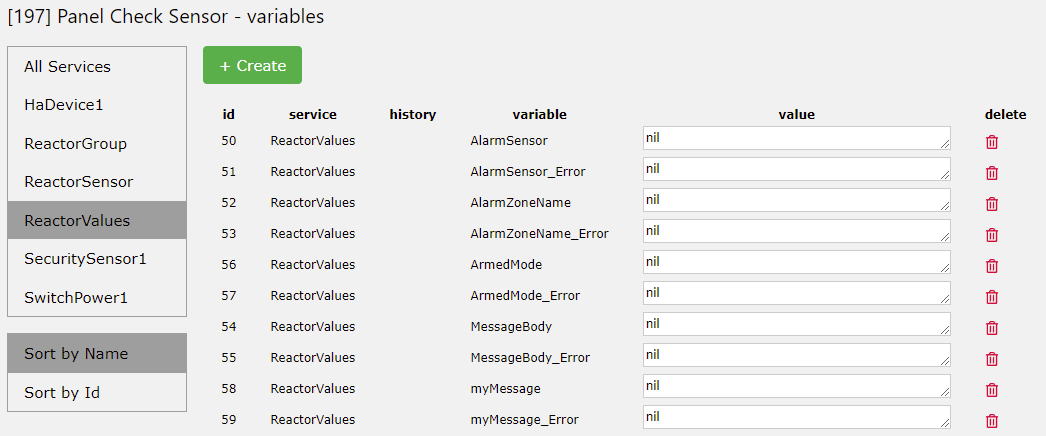




@toggledbits @akbooer Sorry, I will try to be clearer.
" I don't know what "assigning the luup log function to a table" means"
In many of Patrick's plugins, he uses a global lua table to hold plugin data and functions. He assigns shorthand names that call common luup functions, then stores those truncated names in the table. Then the first class functions are called from the table. I believe it is this abstraction that is contributing to log entries that show nil values, as direct calls of "luup.log" do not show nil values. The technique should work in openluup, and most often it does, but sometimes it doesn't.
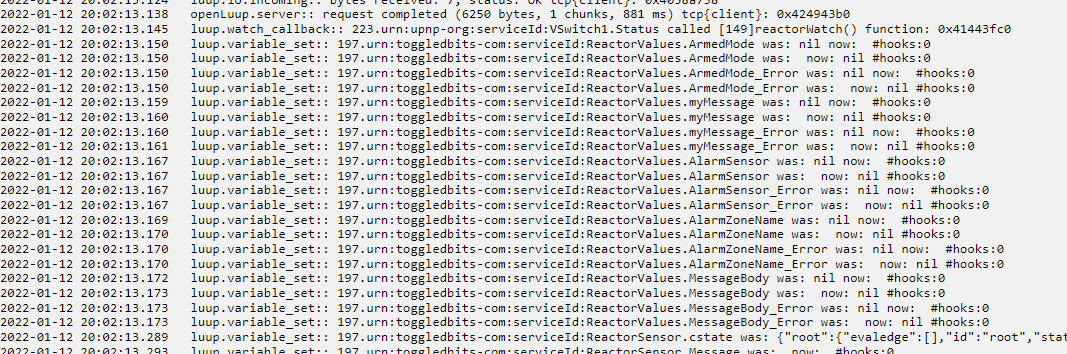
Here's an example from the log where it does not work:
2022-01-15 14:13:12.551 luup.variable_set:: 258.urn:micasaverde-com:serviceId:HaDevice1.CommFailure was: 0 now: 0 #hooks:0
2022-01-15 14:13:12.551 luup.variable_set:: 258.urn:micasaverde-com:serviceId:HaDevice1.CommFailureTime was: 0 now: 0 #hooks:0
2022-01-15 14:13:12.551 luup_log:149: Reactor: Starting nil (#nil)
2022-01-15 14:13:12.551 luup.variable_set:: 149.urn:toggledbits-com:serviceId:Reactor.Message was: Starting Unused1 now: Starting Basic Functions #hooks:0
2022-01-15 14:13:12.552 luup.variable_set:: 265.urn:toggledbits-com:serviceId:ReactorSensor.Invert was: nil now: #hooks:0
2022-01-15 14:13:12.552 luup.variable_set:: 265.urn:toggledbits-com:serviceId:ReactorSensor.Invert was: now: nil #hooks:0
In the log entry "luup_log:149: Reactor: Starting nil (#nil)" the text of the log entry is there "Reactor: Starting", but the variable following the text is nil. This is what I meant by "picking up on variables". The log entries are being displayed, but anything that is a variable is showing as nil. The variables themselves are not actually nil because I can see from program execution that they are doing the job that they're supposed to be doing. It is only in the log entries that they show as nil, at least insofar as what is visible to me.
As for using nil to delete a variable, that seems to be understood and is separate from the log problem.
I believe that this is a scope problem, thus the title of the post. But I don't believe this is a reactor scope problem in that the same issue does not occur on the Vera itself. So for whatever reason, in openLuup, the scope of the variable being displayed in the log is different from the scope of the log function--that the value of the variable is somehow hidden from the function.
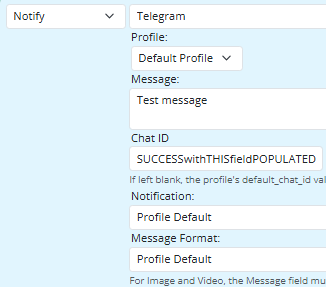
This is a problem as it relates to the readability of the log, an annoyance more than anything, so I have no expectations to have it fixed. In my original screenshots, you can see multiple log entries that display as nil, so that's why I brought this to your attention as I felt that if there are scope issues at work with the logging function, then it could be happening elsewhere as well.
The only other thing that I would add is that in my startup lua, I call a module in the _G space so that I can access functions in the lua section of Reactor activities. My call is _G.myStartUpLua = require("myStartUpLua") I don't believe that this should have an effect on the log, but perhaps it does.