



Guys, the best possible answer is to make our home automation setup work the way we want it in reliable and efficient manner, with or without our EOL veras but with each other's help. That's what we are seeking after all. While keeping our minds open, exploring all the novelties and discussing what we can do to continuously innovate improve and optimize. The vera had an awesome forum with tremendous community of developers. I sensed the end of an era and as much of our time and energy we have spent there, it was not all wasted. The best answer is to move on, not only for the sake of answering but also to refocus on what we aim to do: A community to grow, develop, debate, explore smart home technologies.
rafale77
@rafale77
Love openLuup - it just keeps working perfectly.
I started looking at trying to add a gen4 Shelly device to the Shelly plugin via L_ShellyBridge.lua. The plugin is a little uncooked (no rudeness intended), so a bit of a rabbit hole for me.
All of a sudden no console pages available in either Firefox or Chrome. AltUI works perfectly and all the log files indicate no errors. openLuup still running everything works as it should - just no console pages.
I possibly screwed something up but any recently changes files show no problems. The original/ backup of L_ShellyBridge.lua was reinstated but still no console.
Bit stumped on this one. Not sure how to debug. Any ideas?
Build 21228 has been released. Docker images available from DockerHub as usual, and bare-metal packages here.
Home Assistant up to version 2021.8.6 supported; the online version of the manual will now state the current supported versions;
Fix an error in OWMWeatherController that could cause it to stop updating;
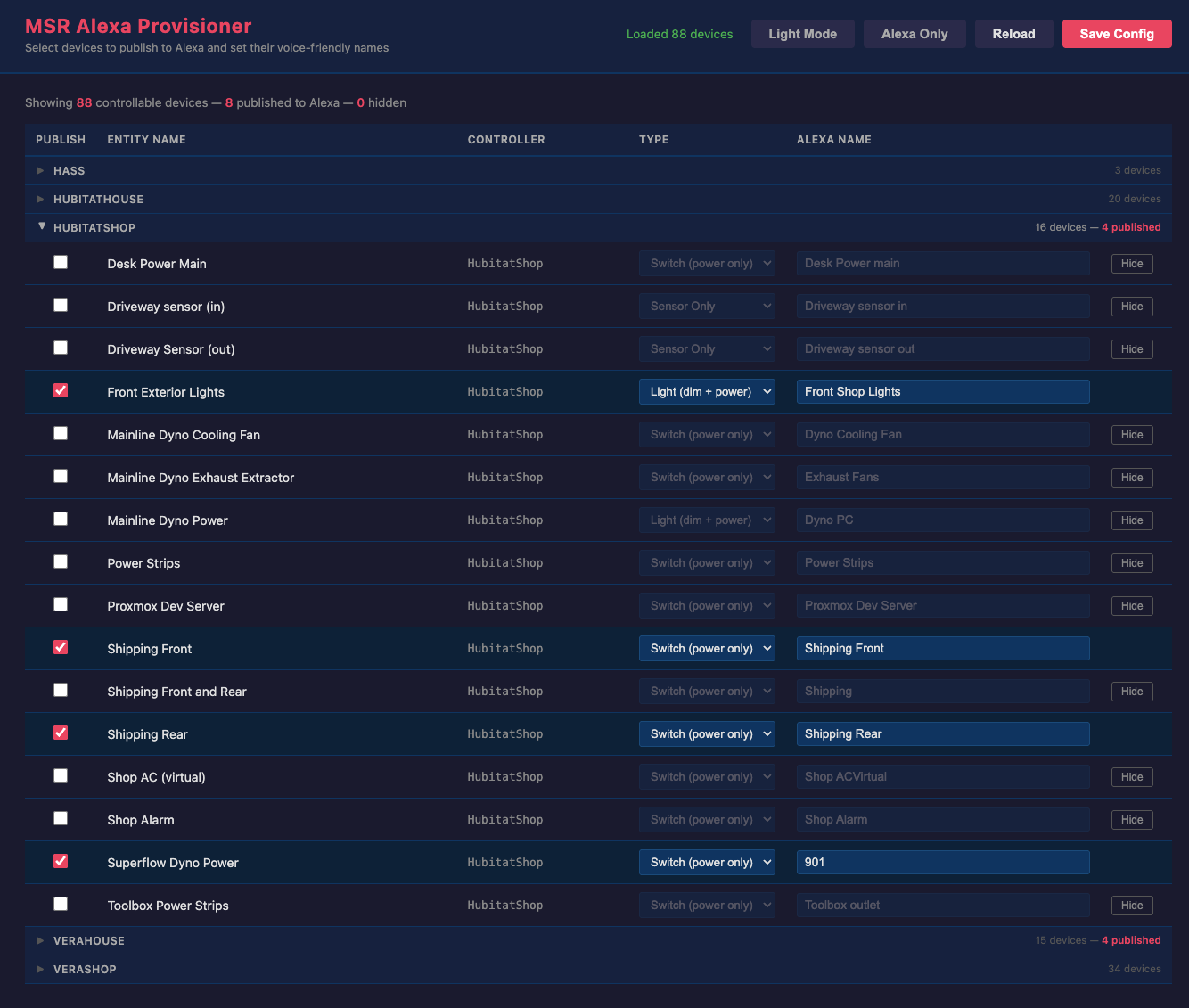
Unify the approach to entity filtering on all hub interface classes (controllers); this works for device entities only; it may be extended to other entities later;
Improve error detail in messages for EzloController during auth phase;
Add isRuleSet() and isRuleEnabled() functions to expressions extensions;
Implement set action for lock and passage capabilities (makes them more easily scriptable in some cases);
Fix a place in the UI where 24-hour time was not being displayed.
Hey @toggledbits
One thing that bothers me while doing work on new systems/new features, is that I cannot copy&paste actions, and I cannot drag&drop between set and resets.
#1 is for when I want to copy an action between different rules opened in two separate browser windows, while #2 is when I just need to flip a bunch of actions in the reset, or move some logic back and forth.
Both will be appreciated, but I understand the technical challenges. Thanks!
I'm currently on version 26011. I understand that the aarch64 image is no longer supported. So, I therefore need to update to the ARM64 image. Can anyone possibly suggest how I update my docker compose.yaml file (see below). Ideally I'd like to keep my existing reactions etc. rather than start from scratch.
# Multi-System Reactor template docker-compose.yml (version 22160)
#
# Change the lines indicated by "DO"...
#
services:
reactor:
container_name: reactor
environment:
# DO change the TZ: line to set your local time zone.
# See valid TZ list: https://en.wikipedia.org/wiki/List_of_tz_database_time_zones
TZ: GB
#
# DO NOT change this path. Your directory location is in "source" below.
REACTOR_DATA_PREFIX: /var/reactor
# DO change the image below to the one you are using (e.g. armv7l or aarch64 for RPi 4)
image: toggledbits/reactor:latest-aarch64
restart: "always"
expose:
- 8111
ports:
- 8111:8111
volumes:
# DO change the /home/username/reactor below to the directory you created for
# your local data; DO NOT change the /var/reactor part
- /home/pi/docker/reactor:/var/reactor
- /etc/localtime:/etc/localtime:ro
tmpfs: /tmp
It appears that Ezlo is going to new levels of paid subscription for cloud services supporting Vera hubs. I have to congratulate them. It will soon be 8 years since Ezlo acquired Vera, and despite their purported financial and "intellectual" capital, they have to date not produced a viable full replacement for Vera. Now they are going to charge extra for services for a platform that they stopped updating years ago.
If you know anyone who hasn't yet fully moved on from Captain Ahab's White Whale Chase, please remind them that my Decouple project is still up on Github to decouple a Vera Plus/Secure/Edge from Vera/Ezlo's cloud services. Veras have been said to misbehave when they can't reach the mother ship.
I have also written my first new Vera plugin in... six years? more?... the AlertPushover project will send Vera hub alerts to Pushover, so you can still get messages generated by your Vera hub without paying for Ezlo's cloud service. It's crude but functional (i.e. better than nothing/worth every penny paid).
These two projects won't replace the functionality of their cloud service and app for those who need those things. But any that don't, this may help bridge the gap. Hopefully these stragglers who have waited so long and been disappointed so often will get the idea that it's time to move on.
If you are using the armv7l docker image, the OpenJS Foundation that publishes node is no longer producing 32-bit builds as of v24. That means the last supported LTS version of node for armv7l is v22, which will go End-of-Life in May 2027.
Therefore, the Reactor armv7l image is now deprecated and will only be produced until node v22 goes EOL, and I will not publish armv7l images beyond that date.
If you are running an RPi 3 or earlier with Reactor, you are on this image, and will need to upgrade hardware to a 64-bit model and use the arm64 image. If you need help getting it done, ask in this category.
@toggledbits I pulled the image (well, Watchtower did) and within minutes the whole system went offline.
The log looks like it ends with 26143.
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-mkahsmgf/26qq82mw-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-lqyfljfi/22f8on0t-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-lsb61rw8/24oenqi2-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-lrh58he0/rule-lrh58he0:S-1c00gfib-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-lrh58he0/1c00dylr-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-lrh58he0/1nam9w5u-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-miuh2qqi/22ls4lql-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-kwc6rmci/rule-kwc6rmci:S-1vj8sdfc-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-kwc6rmci/rule-kwc6rmci:S-1qanz01x-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-ladyja6a/24lq19p6-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-mk0o8iox/23oy468y-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-miscg2h3/rule-miscg2h3:S-22gmbq1c-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#re-kxgrfjke/238p0old-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#re-m7ccsso5/re-m7ccsso5-1r0myjxa-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-ladyja6a/19nl9wq2-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-ladyja6a/rule-ladyja6a:S-yl3xk9t-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-ladyja6a/rule-ladyja6a:S-yl3vv5m-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#re-ln7j2nqp/re-ln7j2nqp-22mx9lzd-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#re-ln7j2nqp/22mx87c8-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-licneppy/1mzwe7ht-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-ml3194ih/25jqt1j4-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#re-kxgrg7kf/227hshak-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-reactorexmachina/13ua1p95-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-reactorexmachina/13uagam7-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-grpvl9oypg/rule-grpvl9oypg:R-134x4cbv-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-grpvl9oypg/rule-grpvl9oypg:R-134x2fyl-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#re-lscjrws1/238p5c22-cons
[latest-26143]2026-05-31T15:23:44.547Z <default:INFO> Closing container Container#Predicate#rule-lbwr0jvq/1xkczf03-cons
[latest-26143]2026-05-31T15:23:44.547Z <Structure:NOTICE> Structure Structure#1 stopped
[latest-26143]2026-05-31T15:23:44.547Z <app:NOTICE> Closing APIs...
[latest-26143]2026-05-31T15:23:44.547Z <wsapi:NOTICE> wsapi: closing...
[latest-26143]2026-05-31T15:23:44.547Z <wsapi:NOTICE> wsapi: disconnecting from "192.168.1.23#82" (1001 service closing)
[latest-26143]2026-05-31T15:23:44.548Z <httpapi:NOTICE> HTTP API closing...
[latest-26143]2026-05-31T15:23:44.549Z <wsapi:NOTICE> wsapi: server closed
[latest-26143]2026-05-31T15:23:44.549Z <httpapi:INFO> HTTP server closed.
[latest-26143]2026-05-31T15:23:44.549Z <app:NOTICE> Stopping timers...
[latest-26143]2026-05-31T15:23:44.551Z <app:null> Shutdown complete, process ID 1
[latest-26143]2026-05-31T15:23:44.551Z <app:null> Closing logs...
[latest-26143]2026-05-31T15:23:44.551Z <default:null> Closing log
I can SSH to the VM. Alas, I do not have the previous image for 26143 as I'm a little too quick sometimes on housekeeping.
Today marks another milestone in my Home Automation journey.
After tripping the main breaker once, and shedding more blood than is normally recommended, the underfloor heating (which was the last Z-wave device on my system) has been replaced with a Zigbee one.
Edited reactor.conf
Disabled z-way-server
Disabled Openluup
Z-wave is no more....
C
Posts
-
Vera account suspended for a 1000 years -
Forum Mission StatementWho are we, what is our purpose? A community of smart home user or fans who felt the need for an independent place to share our experience, discuss novelties and ideas and test/develop better tools for home automation. Many of us come from the old Vera community but feel there is a space for non-partisan space to discuss the technology.
Everybody from any platform is welcome to discuss and share even though many of us are starting from the Vera and its much improved derivate, openLuup. We would only ask to for everyone to remain respectful and courteous to one another. Yes! even technical discussions can become heated as opinions can conflict. We respect everyone’s opinion and decisions and expect the same from others.
This forum is hosted benevolently by long time Vera community member DesT.
-
Not so quiet around here :)@perh said in Not so quiet around here
") :
:I've asked for them to delete my account, but they say "the jury's still out" in the case of the "SHC mutineers".

")
Did they actually use the term "mutineers" there?
Are they actually serious? Do they still think that we are properties/employees/soldiers they should have any sort of control over? I hope not.They are booting the most loyal customers, ones who are willing to spend their time providing free customer support to others, sharing their fixes and findings to the community. Customers who are also providing them feedback to make their products better... He forced the creation of this forum with censorship then accuses people of all kinds of things and now is surprised that people are leaving?

Trust me only a very small number of those who have left are here. Many more are on many other platforms ranging from Homeseer to Hubitat to Home Assistant. And the cold hard truth is, that everyone has been much better off after leaving, has a much more reliable and capable system and for those who rely on community forums, have a place to discuss and have fun learning again.
-
openLuup IconsThis is a set of openLuup icons to replace the ones which you normally would transfer over from the vera. The only thing for the dimmable lights is that one needs to use a new json file to replace the original light bulb with an vector graphics type which I am also sharing.
icons.zip
D_DimmableLight1.json.zipThis is a sample of the icons on ALTUI:

-
zwaveserialNever posted this on the vera forum but...
Did you know about this?The vera has a very powerful zwaveserial API program in the firmware. Take a look at what it can do:
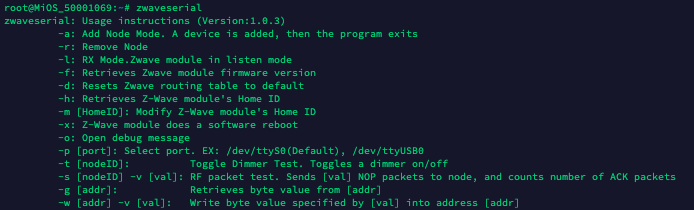
It is what the UI calls to interface with the zwave dongle.
-
Not so quiet around here :)Been trying to refrain myself from replying but here we go...
Instead of repeating what I have said in the past, my view is that ezlo and its leader have a very different view of the market and possibly do not understand what they bought by merging vera.But the basics are:
"But what can you do. Both sides have done things to upset the other."
Sorry but one has to put the context as to who is who back in place here. There is no circumstance under which a business owner should ever treat their customers this way. For anyone running a business, if a customer is upset, you should first asking why. Instead the guy keeps doing what upsets his customers and starts insulting and calling them names. That's unprofessional and unheard of."I think he feels you are all against the Ezlo platform and its future success and you just want your Vera firmware as is, to hack."
Again, instead of feeling this way, he should be asking why? Being the one who tore down the firmware down to the OS level, I think I can speak of it. Certainly "as is" is incorrect. The whys:
- Because it's broken
- Most of the fixes are trivial
- They significantly improve the vera
- They are not fixing it themselves.
Now on the understanding of this home automation market. If you run a market survey, you will see that the vast majority if not all platforms today rely to various degree on community development of external integration, cloud or local, and run on increasingly more powerful hardware. When they bought vera, they inherited a community, a small remnant of hardcore users who have extended the life of the vera to its limits trying to maintain the platform on par with the competition but still somewhat behind. A large number of people have already jumped ship quietly. The most vocal people on the forum are the most loyal supporters of the platform and many stay because of the technical migration barrier to other platforms. I think we were all excited about the prospective of a new hub and an updated platform. I was all in. There are however two bare minimum critical requirements to a new hub:
- Functional equivalency, including all the integrations the plugins supported
- An ease of migration from a vera installation to the new hub.
Sadly what I have observed is a complete disdain of these basic requirements and a development strategy aiming straight down the toilet (excessive focus on mobile app and cloud base processing, disregard of the critical wireless stacks and repeat of past mistakes in conception of the API) while the current product gets increasingly far behind competitive platforms, including open source ones. I kept an open mind, not being an expert on the software side but expressing a lot of concerns. The increasing amount of spamming of the forum with "exciting breakthroughs" and "pure innovations" of things the community has been able to do and better/faster/simpler for years combined with the release of an underwhelming hardware for the new controller, clearly pointing to a focus on minimum cost at the compromise of extendibility and reliability and you can clearly see my disappointment. That was the last straw for me. I predicted last year that the platform would not be ready in a year because of their approach... look at where they are now.
In the meantime, I have moved my zwave network to z-way. Stunningly, the migration is easier than to go from vera to ezlo and it felt like jumping from the stone age to science fiction. Everything became lighning fast... All my secure class problems and latency issues gone. I can no longer find any unsupported devices... etc... And all of my previous integrations are retained and more. So yeah I can see why he is upset but he can only be so at himself. Taking it out on his most loyal customers is... well you're the judge. -
Object RecognitionAnd... it is done! My outdoors IP Cams no longer just detect motion... They detect people, packages, and cars and are now used as openLuup scene triggers!
-
System integration roadmap -
Nuke Vera ScriptScript to disable all the mios/vera proprietary program and broadcast its zwave and zigbee radio serial ports in your network so it can be picked up by another controller... For example z-way.
 GitHub - rafale77/Nuke-Vera: Script to neuter the vera and broadcast its zwave and zigbee serial ports
GitHub - rafale77/Nuke-Vera: Script to neuter the vera and broadcast its zwave and zigbee serial ports
Script to neuter the vera and broadcast its zwave and zigbee serial ports - rafale77/Nuke-Vera
-
Import vera most important topicsThinking about it, I don't think we should be importing posts without the consent of their authors so... I am rewriting, resharing a compacted version of my posts.

-
z-way-server 3.1.0 release lol, yes I can imagine. So far I am seeing a few cosmetic improvements on this new version but since I am rarely ever interacting with the z-way UI, it isn't doing much for me. The upgrade went pretty smoothly though it had to be a little manual.
For those who want to do it on debian/ubuntu, the process is to download the file:wget https://storage.z-wave.me/z-way-server/z-way-server-Ubuntu-v3.1.0.tgzdecompress it:
tar -zxf z-way-server-Ubuntu-v3.1.0.tgzremove the default config file:
rm z-way-server/automation/storage/*.jsonand then overwrite the z-way-server installation folder wherever it is. Mine is in the /opt folder which requires root permission.
sudo cp -r z-way-server /opt/PS: One notable improvement is in the noise meter. Now the below detection limit shows up as -95dBm instead of a nil value which made the graph looked like the noise remained at a high level. I think it was one of my requests...
-
Vera account suspended for a 1000 yearsYeah really don't miss the old forum thanks to @DesT!
Live and let ... be.
Happy as clam with my zwave and zigbee setup honestly... and to not have had to exclude/re-include anything to get there was a major part of it, given the size of my network. -
Other Forum feedback -
Vera account suspended for a 1000 years@akbooer said in Vera account suspended for a 1000 years:
Clearly deranged. All I ever wanted to do was support openLuup users, and point out that, under the new regime, that was best done here rather than there!
Didn't need to explain AK. The guy shows us something green and tells us that it is orange. It's be going on since I was there. Everybody else can see that it is green...
@dest said in Vera account suspended for a 1000 years:
Some people are having way too much free time
And not enough neurons...
Talk about forum rules.. so many he made up to justify banning people giving feedback and expressing their problems and obviously not applying them to himself. Community users are not possessions or employees... they are customers. He is dictating that everyone be happy with the trash and lies he is feeding people without asking why customers are unhappy. Honest customer feedback is essential to success. In my line of work, we don't let ourselves make a single customer unhappy... not one.
Let him be.
-
Vera account suspended for a 1000 yearsAnd I do want to say for the record, the post which got me banned over there was about 2 things:
- A response to a link to the review article for the ezlo USB powered dongle which obviously was written by a home automation newb journalist who knew nothing about it, making claims which were obviously untrue as I had one on hand myself. I called that false advertising.
- The fact that the ezlo controllers, the ezlo plus was an obvious cost reduced version of the vera plus with everything that matters downgraded and everything which is unimportant brought up to date for cost reduction. It is basically a toy grade device barely good enough as a toy for my then 8 year old lego projects. I was pretty sad seeing all the people spending time and money on 3D printing for a shell which is likely worth more than the content. I am a hardware enthusiast working in the semiconductor industry and am pretty well versed in the grade of these chips, who makes them and how. That was my honest feedback. So I called out the false advertising and the forum spamming.
There is nothing wrong with the hardware of the vera. It is actually a very cleverly designed piece of hardware based on a wireless router which was not utilized appropriately by its mcv firmware developers. Unlike the ezlo, it uses SLC NAND which is bears >100x write cycle lifetime than the garbage ezlo put out (the partitioning of the vera storage was the main problem). It uses an appliance grade CPU which is much more reliable than the toy grade junk in the ezlo plus you can buy as a full system for $7 on aliexpress. I could tell from the build of material that it was reallly a cost reduced and downgraded from the vera plus from the build of material and would have never even tried to run my home on it even someone paid me to do it. The only reason why I am no longer using the vera plus as a radio for openLuup/home assistant or z-way is that I got tired of how prone to bricking these embedded devices are. They take a lot more work to recover when there is a storage problem (data corruption etc) so I went low cost x86/x86 which often can be more energy efficient but are always more cost effective and more reliable.
-
Vera account suspended for a 1000 yearsWarm welcome for your first post! This forum only exists thanks to the generosity of @DesT who provided the domain name, hosting and design! We should also be grateful to the venerable mcv/vera for connecting so many people and pioneering this hobby.
-
Vera firmware 7.32 betaI have been mostly silent on this forum for some time now with the exception of the occasional notifications for questions addressed to me because I just moved to a new house and my system had been rock solid for over a year... mostly since I got rid of the vera.
I now have to re-build everything from scratch in my new house while I had literally zero reliability issues with my previous setup in spite of its complexity (200+ devices integrated running 3 different software platform interconnected between z-way for zwave, Homeassistant for AI/cameras and the rare cloud integrations or integrations not existing on openLuup/vera and openLuup for scenes/automation/control interface.)
I considered long and hard to sell my old home with the automation but at the end I decided to move as much as I could over mostly because I noticed an increasing trend of the industry to go towards wifi for ease of setup but which cannot scale to large installations and have to encroach into wifi bandwidth. It is getting a bit harder to buy zwave and even zigbee devices. I also didn't want to spend the time to go through the learning curve of hubitat which would have yielded no benefit to my setup.
Dumping the vera was the single biggest improvement to my system and please, no ezlo... They are cost reduced and downgraded controllers to the vera in every important practical aspect.My new setup will be much lighter. Probably will not get to 175 zwave nodes, more likely <100 without the window coverings, fewer lights, fewer sensors. Heck I think I will dump the Phillips hue altogether too. I can't recommend enough migrating away from vera and go to openLuup or MSR in combination with Home Assistant for zigbee and integrations and z-way for z-wave while keeping devices as local as possible by avoiding all the wifi stuff which tend to be cloud dependent (with all their reliability and security disadvantages) and less efficient both in power and RF bandwidth. Still a new adventure...
-
Network Key LocationUseful for migration from a vera zwave network to z-way.
Find the vera's S0 network key, close the z-way-server and input the key into the
z-way-server/config/zddx/homeid-DeviceData.xml line 147 at the end of the line networkKey replacing the one z-way created by default when you loaded your uzb on it for the first time.
(replace homeid with your homeid after you already migrated the dongle data from the vera to the uzb and already booted z-way at least once) -
Facial recognition triggering automationI have optimized my facial recognition scheme and discovered a few things:
My wifi doorbell, the RCA HSDB2, was overloaded by having to provide too many concurrent rtsp streams which was causing the streams themselves to be unreliable:
Cloud stream
stream to QNAP NVR
stream to home assistant (regular)
stream to home assistant facial recognition.I decided to use the proxy function of the QNAP NVR to now only pull 2 streams from the doorbell and have the NVR be the source for home assistant. This stabilized the system quite a bit.
The second optimization was to find out that by default home assistant processes images every 10s. It made me think that the processing was slow but it turns out that it was just not being triggered frequently enough. I turned it up to 2s and now I have a working automation to trigger an openLuup scene, triggering opening a doorlock with conditionals on house mode and geofence. Now I am looking to offload this processing from the cpu to an intel NCS2 stick so I might test some other components than Dlib to make things run even faster.
-
openLuup HangsSorry for reviving this @akbooer but I wanted to give a quick update on lua socket.
I realized that the library used by luarocks is very old (3.0 RC1 from 2013) and that the apt debian/ubuntu version is a little newer (March 2015). The library has since gone through 5 years of development and I just installed the latest github version using this command:luarocks install luasocket --server https://luarocks.org/devIt compiles the library from the current GitHub master. I am not sure it will help but so far it has not hurt. Will test further...